Hvordan bygge GDPR-sikre AI-applikasjoner med privat EU-inferens
Introduksjon: AI-adopsjon møter compliance-virkelighet
Kunstig intelligens har flyttet fra eksperimenter til produksjonssystemer. Søkeassistenter, automatiseringsarbeidsflyter og beslutningsstøtteverktøy er nå en del av daglig drift.
For team som opererer i Europa, eller betjener europeiske brukere, blir én begrensning uunngåelig: hvor AI-inferens skjer betyr like mye som hva modellen kan gjøre.
Selv når underliggende data er offentlig, krever brukerforespørsler, intensjoner og interaksjonsmønstre nøye håndtering. Denne guiden forklarer hvordan privat EU-basert AI-inferens kan brukes til å bygge konforme, praktiske AI-applikasjoner ved bruk av retrieval-augmented generation (RAG).
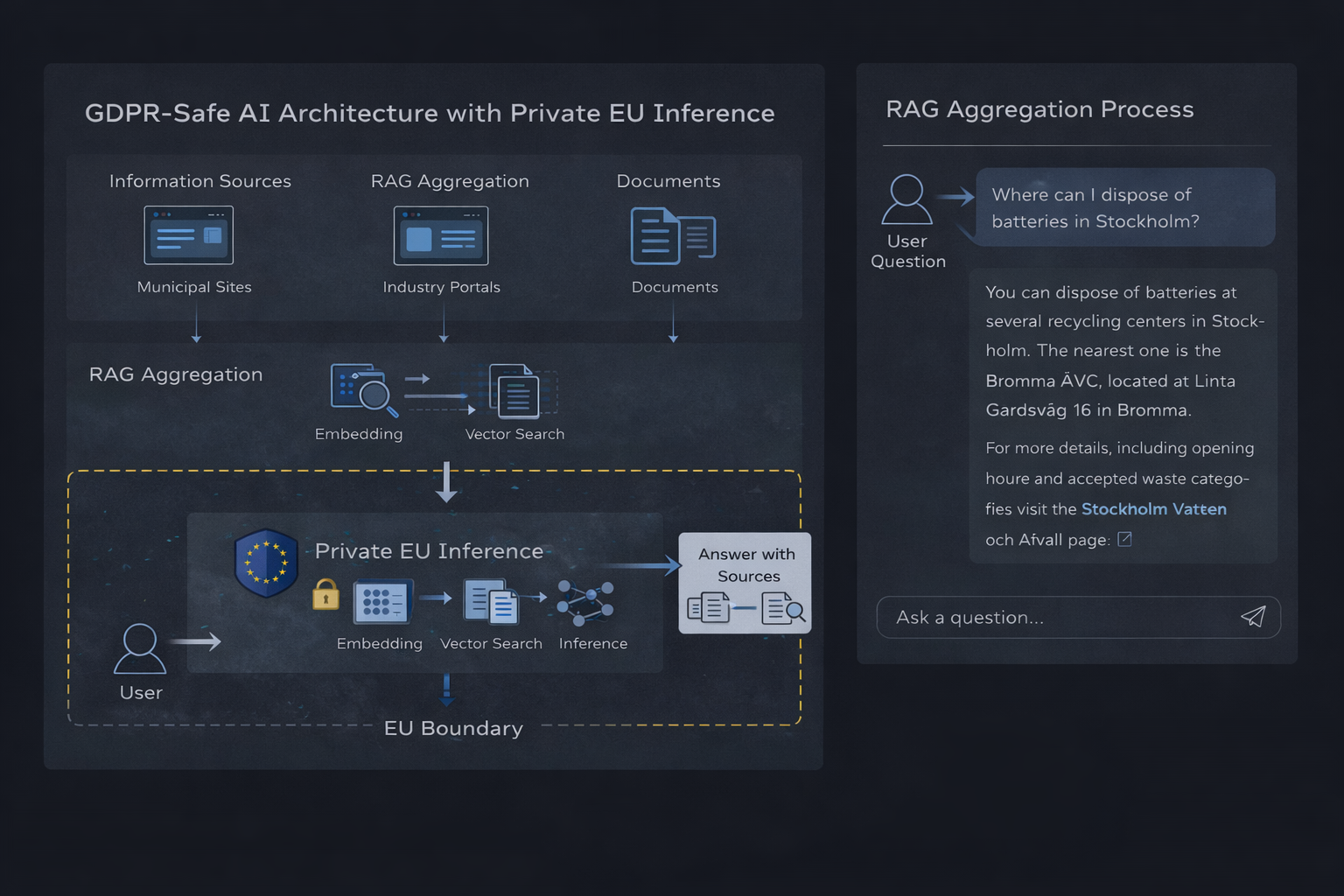 Privat EU-basert AI-inferens-arkitektur med RAG-aggregering
Privat EU-basert AI-inferens-arkitektur med RAG-aggregering
Når privat AI-inferens er riktig valg
Privat AI-inferens er ikke påkrevd for hver brukssak. Det blir relevant når applikasjoner må operere innenfor klare datagrenser, forutsigbar styring og eksplisitte compliance-begrensninger.
Typiske scenarier inkluderer offentlige informasjonstjenester, interne kunnskapssystemer, automatiseringspipelines og regulerte miljøer der datalokalisering og prosesseringskontroll ikke er til forhandling.
Juicefactory.ai tilbyr en privat inferens-runtime lokalisert i EU, spesielt utformet for disse scenariene. Systemet lagrer ikke persondata og bruker ikke kundedata til modelltrening. Dens rolle er begrenset til kun inferens.
Teknisk arkitektur: retrieval-augmented generation
Retrieval-augmented generation kombinerer tradisjonell søk med språkmodellresonnering. I stedet for å spørre en modell om å svare fritt, henter systemet verifisert kontekst og begrenser svaret til den informasjonen.
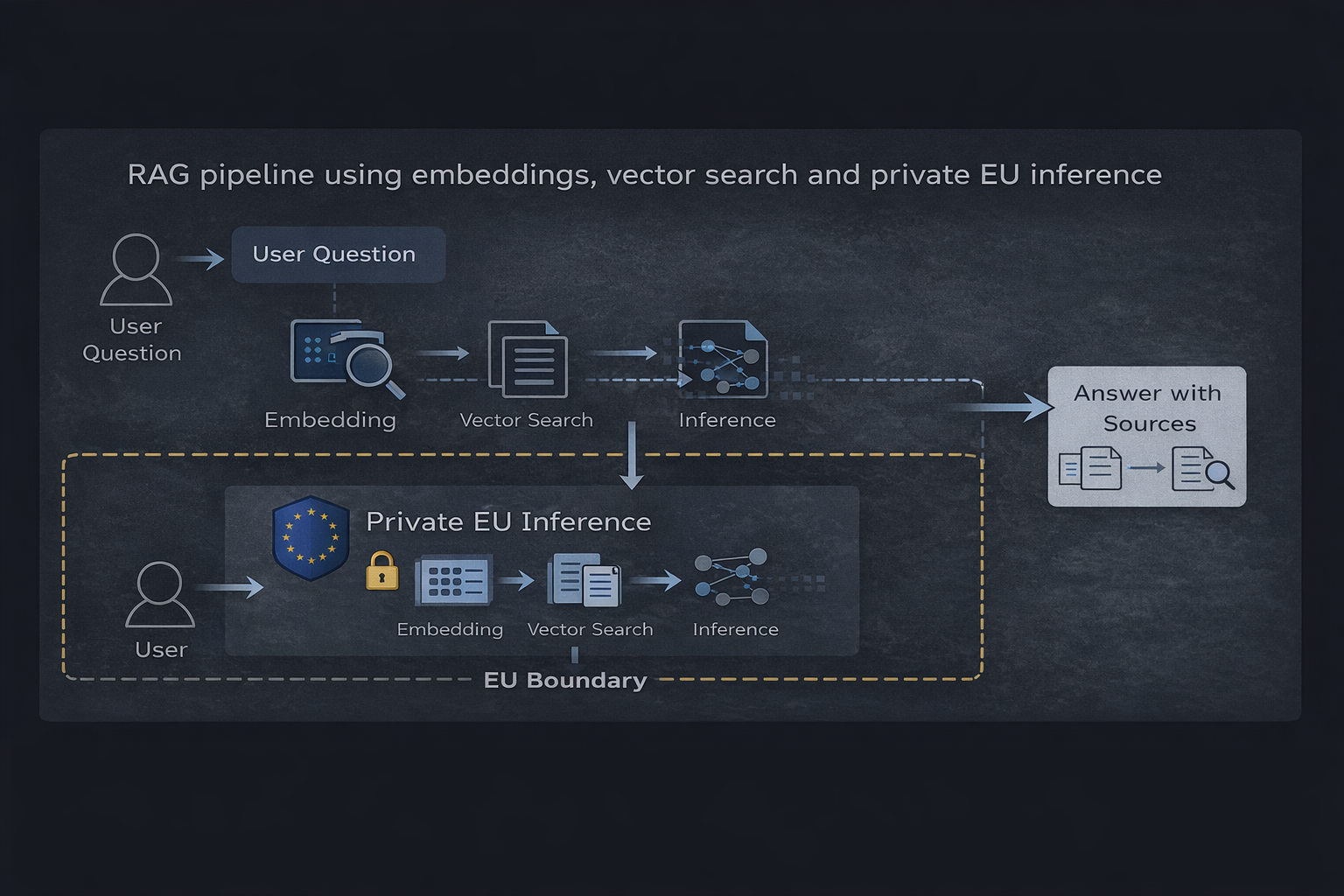 RAG-pipeline som bruker embeddings, vektorsøk og privat EU-inferens
RAG-pipeline som bruker embeddings, vektorsøk og privat EU-inferens
Kjernekomponenter
- En vektordatabase (som Qdrant) som lagrer indeksert innhold
- Embeddings brukt til å representere dokumenter og spørsmål
- Et hentingslag som velger relevant kontekst
- En privat inferens-runtime som genererer begrunnede svar
Flyten er enkel: et brukerspørsmål innbygges, relevant informasjon hentes og modellen produserer et svar basert kun på den konteksten.
Praktisk eksempel: forenkle tilgang til offentlig informasjon
Offentlig informasjon er ofte distribuert på tvers av mange autoritative kilder. Kommunale nettsider, bransjeportaler og offisielle dokumenter kan alle inneholde korrekt informasjon, men likevel være vanskelig for brukere å navigere.
Et praktisk eksempel på denne tilnærmingen kan sees i et virkelig eksperiment som utforsker hvordan AI kan forenkle tilgang til nasjonalt fragmentert informasjon uten å erstatte lokal autoritet.
Systemet henter relevant innhold, genererer en forklaring og peker brukere mot riktig autoritativ kilde — reduserer friksjon samtidig som tillit bevares.
 Eksempel på en live offentlig-informasjonsassistent som bruker retrieval-augmented generation og privat EU-basert inferens.
Eksempel på en live offentlig-informasjonsassistent som bruker retrieval-augmented generation og privat EU-basert inferens.
Hvorfor inferens-lokasjon betyr noe for GDPR
Selv når underliggende innhold er offentlig, tolker inferensprosessen brukerintensjon og kontekstuelle forespørsler. Denne prosesseringen kan falle under GDPR-hensyn, noe som gjør inferens-lokasjon og datahåndteringspraksis kritisk.
Å kjøre inferens innenfor EU gir klarere regulatoriske grenser, forutsigbar styring og større gjennomsiktighet for både operatører og brukere.
Oppsummering
Privat EU-basert AI-inferens gjør det mulig å kombinere moderne AI-evner med ansvarlig datahåndtering. Ved å pare retrieval-augmented generation med en kontrollert inferens-runtime, kan team bygge nyttige, konforme systemer uten å ofre brukervennlighet eller kontroll.
Utforsk hvordan erstatning av eksterne inferens-leverandører med EU-basert infrastruktur fungerer i praksis, eller lær hvordan automatiseringsarbeidsflyter integreres med privat AI for ende-til-ende compliance.