Come costruire applicazioni AI conformi al GDPR utilizzando inferenza privata nell'UE
Introduzione: L'adozione dell'AI incontra la realtà della conformità
L'intelligenza artificiale è passata dagli esperimenti ai sistemi di produzione. Assistenti di ricerca, flussi di lavoro di automazione e strumenti di supporto alle decisioni fanno ora parte delle operazioni quotidiane.
Per i team che operano in Europa, o che servono utenti europei, un vincolo diventa inevitabile: dove avviene l'inferenza AI è importante quanto ciò che il modello può fare.
Anche quando i dati sottostanti sono pubblici, le query degli utenti, le intenzioni e i modelli di interazione richiedono un trattamento accurato. Questa guida spiega come l'inferenza AI privata basata nell'UE può essere utilizzata per costruire applicazioni AI conformi e pratiche utilizzando la generazione aumentata dal recupero (RAG).
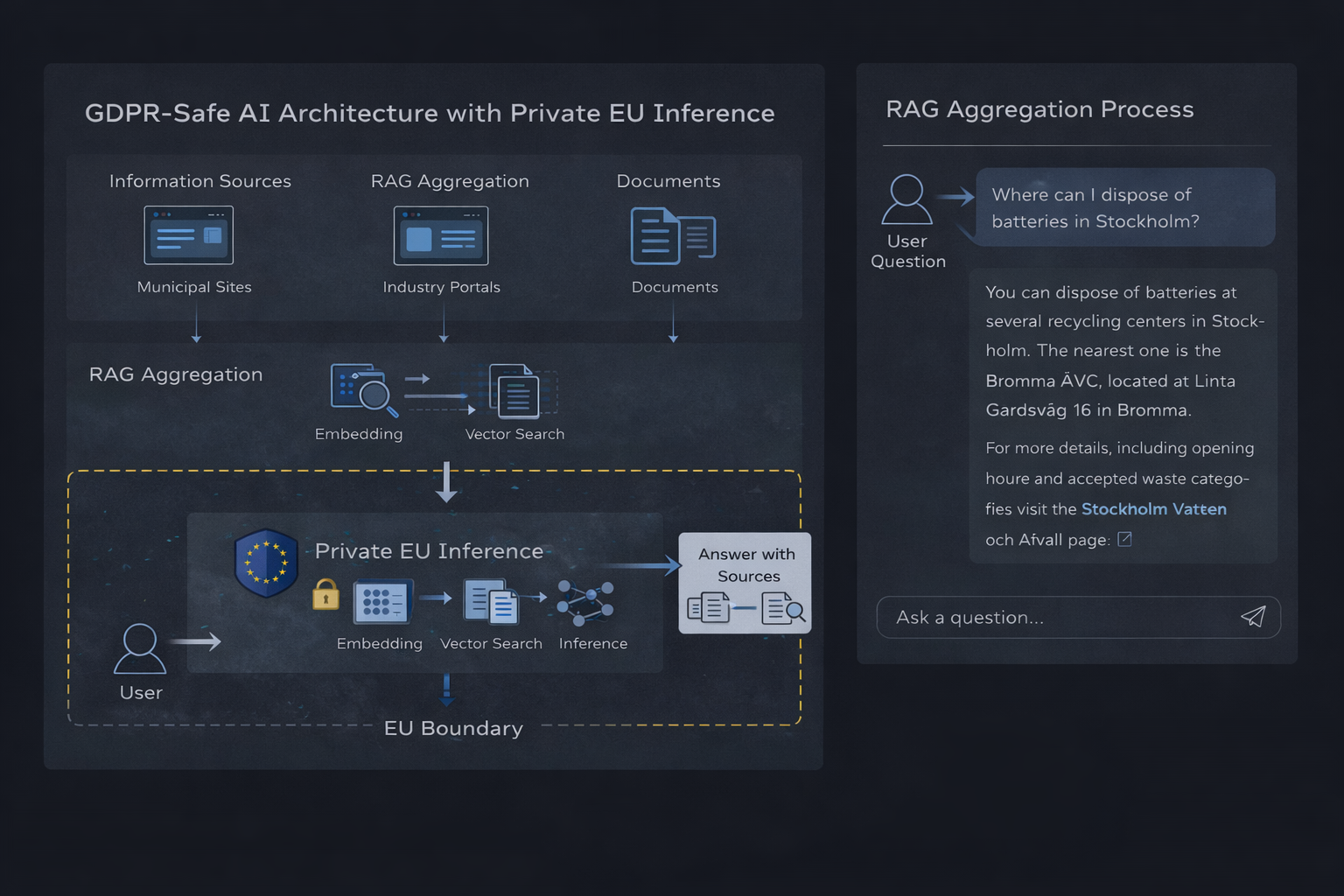 Architettura di inferenza AI privata basata nell'UE con aggregazione RAG
Architettura di inferenza AI privata basata nell'UE con aggregazione RAG
Quando l'inferenza AI privata è la scelta giusta
L'inferenza AI privata non è richiesta per ogni caso d'uso. Diventa rilevante quando le applicazioni devono operare entro chiari confini di dati, governance prevedibile e vincoli di conformità espliciti.
Gli scenari tipici includono servizi di informazione pubblica, sistemi di conoscenza interni, pipeline di automazione e ambienti regolamentati dove la localizzazione dei dati e il controllo dell'elaborazione non sono negoziabili.
Juicefactory.ai fornisce un runtime di inferenza privata situato nell'UE, progettato specificamente per questi scenari. Il sistema non memorizza dati personali e non utilizza i dati dei clienti per l'addestramento dei modelli. Il suo ruolo è limitato solo all'inferenza.
Architettura tecnica: generazione aumentata dal recupero
La generazione aumentata dal recupero combina la ricerca tradizionale con il ragionamento del modello linguistico. Invece di chiedere a un modello di rispondere liberamente, il sistema recupera contesto verificato e vincola la risposta a quelle informazioni.
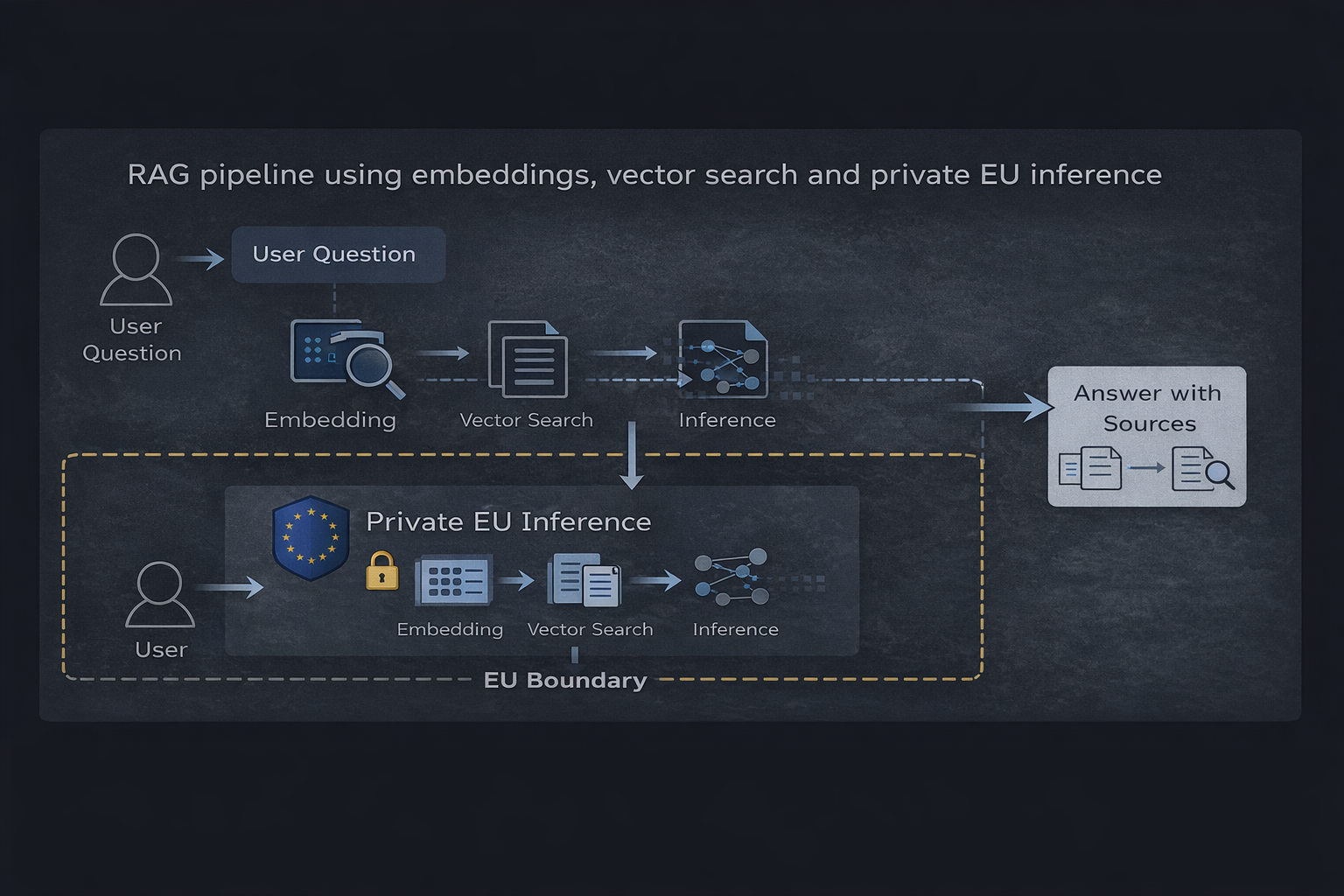 Pipeline RAG che utilizza embeddings, ricerca vettoriale e inferenza privata nell'UE
Pipeline RAG che utilizza embeddings, ricerca vettoriale e inferenza privata nell'UE
Componenti principali
- Un database vettoriale (come Qdrant) che memorizza contenuto indicizzato
- Embeddings utilizzati per rappresentare documenti e domande
- Uno strato di recupero che seleziona contesto rilevante
- Un runtime di inferenza privata che genera risposte fondate
Il flusso è semplice: una domanda dell'utente viene incorporata, le informazioni rilevanti vengono recuperate e il modello produce una risposta basata solo su quel contesto.
Esempio pratico: semplificare l'accesso alle informazioni pubbliche
Le informazioni pubbliche sono spesso distribuite su molte fonti autorevoli. Siti web comunali, portali di settore e documenti ufficiali possono tutti contenere informazioni corrette, ma essere ancora difficili da navigare per gli utenti.
Un esempio pratico di questo approccio può essere visto in un esperimento del mondo reale che esplora come l'AI può semplificare l'accesso a informazioni nazionalmente frammentate senza sostituire l'autorità locale.
Il sistema recupera contenuto rilevante, genera una spiegazione e indirizza gli utenti alla fonte autorevole corretta — riducendo l'attrito preservando la fiducia.
 Esempio di un assistente di informazione pubblica live che utilizza generazione aumentata dal recupero e inferenza privata basata nell'UE.
Esempio di un assistente di informazione pubblica live che utilizza generazione aumentata dal recupero e inferenza privata basata nell'UE.
Perché la posizione dell'inferenza è importante per il GDPR
Anche quando il contenuto sottostante è pubblico, il processo di inferenza interpreta l'intenzione dell'utente e le query contestuali. Questa elaborazione può rientrare nelle considerazioni GDPR, rendendo critici la posizione dell'inferenza e le pratiche di gestione dei dati.
Eseguire l'inferenza all'interno dell'UE fornisce confini normativi più chiari, governance prevedibile e maggiore trasparenza sia per gli operatori che per gli utenti.
Riepilogo
L'inferenza AI privata basata nell'UE rende possibile combinare le moderne capacità dell'AI con una gestione responsabile dei dati. Accoppiando la generazione aumentata dal recupero con un runtime di inferenza controllato, i team possono costruire sistemi utili e conformi senza sacrificare usabilità o controllo.
Esplora come sostituire i fornitori di inferenza esterni con infrastruttura basata nell'UE funziona in pratica, o scopri come i flussi di lavoro di automazione si integrano con l'AI privata per la conformità end-to-end.