Cómo construir aplicaciones de IA compatibles con GDPR usando inferencia privada en la UE
Introducción: La adopción de IA se encuentra con la realidad del cumplimiento
La inteligencia artificial ha pasado de los experimentos a los sistemas de producción. Los asistentes de búsqueda, los flujos de trabajo de automatización y las herramientas de apoyo a la toma de decisiones son ahora parte de las operaciones diarias.
Para los equipos que operan en Europa, o que sirven a usuarios europeos, una restricción se vuelve inevitable: dónde ocurre la inferencia de IA importa tanto como lo que el modelo puede hacer.
Incluso cuando los datos subyacentes son públicos, las consultas de los usuarios, las intenciones y los patrones de interacción requieren un manejo cuidadoso. Esta guía explica cómo la inferencia de IA privada basada en la UE puede usarse para construir aplicaciones de IA prácticas y conformes utilizando la generación aumentada por recuperación (RAG).
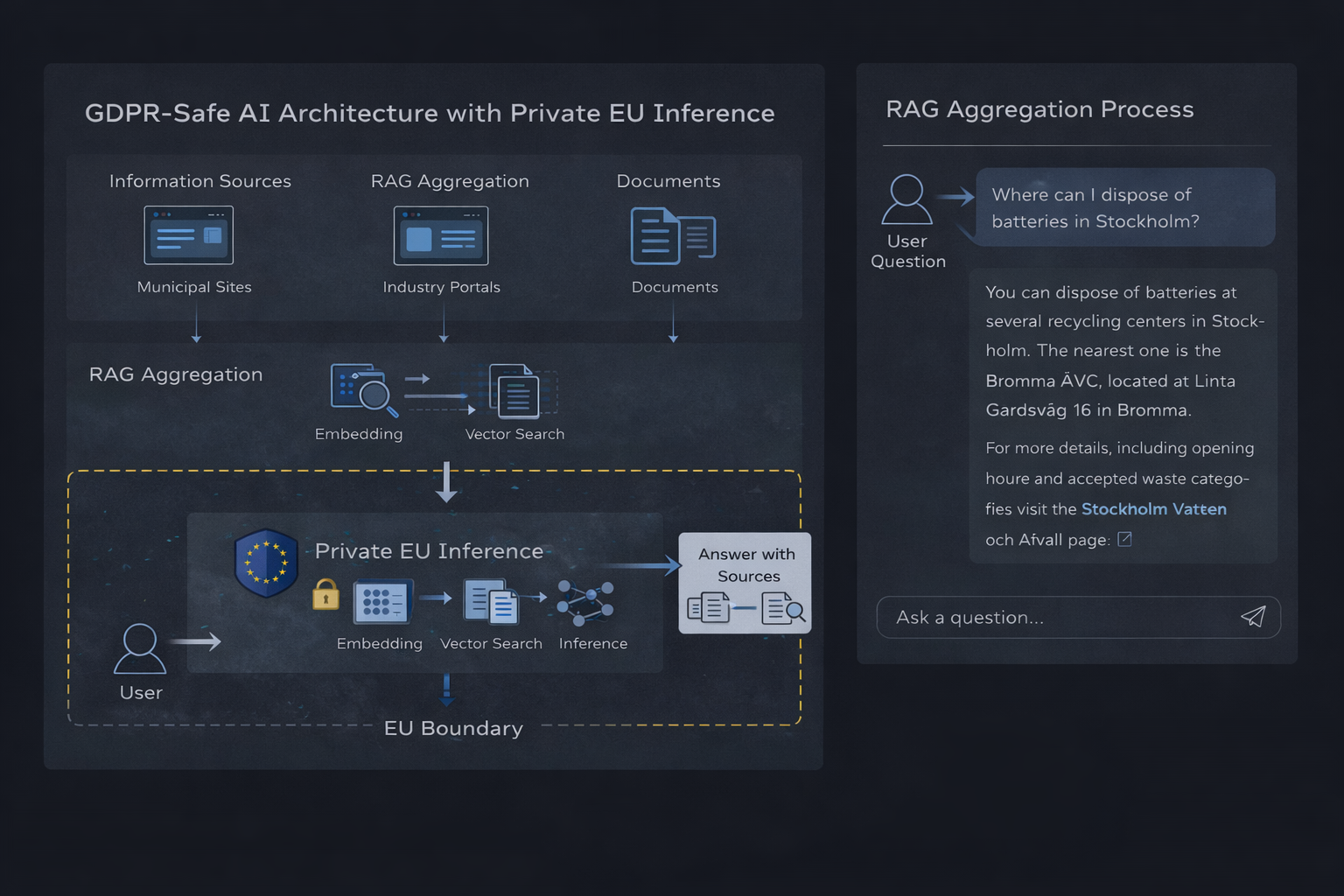 Arquitectura de inferencia de IA privada basada en la UE con agregación RAG
Arquitectura de inferencia de IA privada basada en la UE con agregación RAG
Cuándo la inferencia de IA privada es la elección correcta
La inferencia de IA privada no es requerida para cada caso de uso. Se vuelve relevante cuando las aplicaciones deben operar dentro de límites de datos claros, gobernanza predecible y restricciones de cumplimiento explícitas.
Los escenarios típicos incluyen servicios de información pública, sistemas de conocimiento internos, pipelines de automatización y entornos regulados donde la localización de datos y el control de procesamiento no son negociables.
Juicefactory.ai proporciona un runtime de inferencia privada ubicado en la UE, diseñado específicamente para estos escenarios. El sistema no almacena datos personales y no usa datos de clientes para el entrenamiento del modelo. Su rol está limitado solo a la inferencia.
Arquitectura técnica: generación aumentada por recuperación
La generación aumentada por recuperación combina la búsqueda tradicional con el razonamiento del modelo de lenguaje. En lugar de pedirle a un modelo que responda libremente, el sistema recupera contexto verificado y limita la respuesta a esa información.
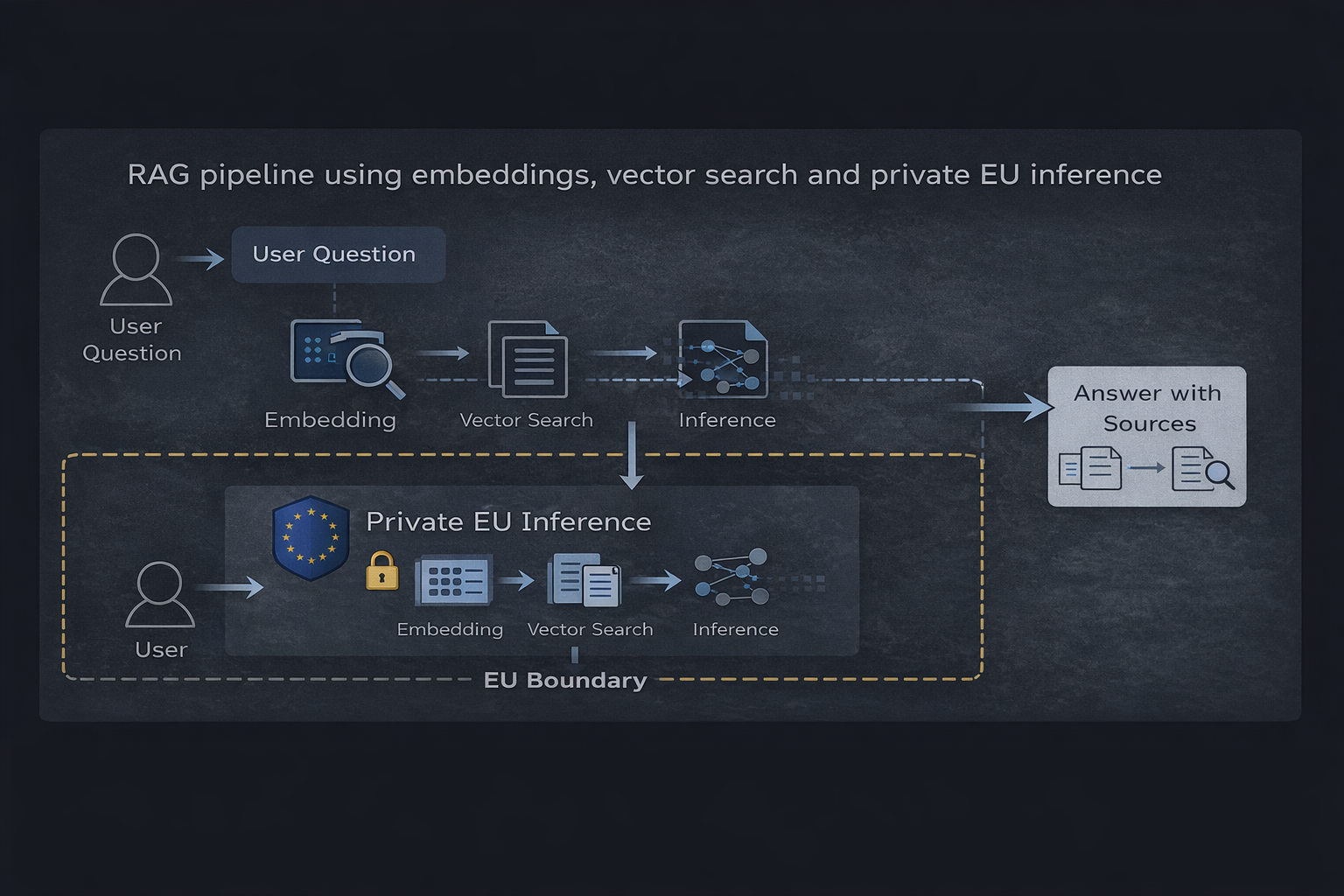 Pipeline RAG usando embeddings, búsqueda vectorial e inferencia privada en la UE
Pipeline RAG usando embeddings, búsqueda vectorial e inferencia privada en la UE
Componentes principales
- Una base de datos vectorial (como Qdrant) que almacena contenido indexado
- Embeddings usados para representar documentos y preguntas
- Una capa de recuperación que selecciona contexto relevante
- Un runtime de inferencia privada que genera respuestas fundamentadas
El flujo es simple: una pregunta del usuario se incrusta, se recupera información relevante y el modelo produce una respuesta basada solo en ese contexto.
Ejemplo práctico: simplificar el acceso a la información pública
La información pública a menudo está distribuida en muchas fuentes autorizadas. Los sitios web municipales, los portales de la industria y los documentos oficiales pueden contener información correcta, pero aún así ser difíciles de navegar para los usuarios.
Un ejemplo práctico de este enfoque se puede ver en un experimento del mundo real que explora cómo la IA puede simplificar el acceso a información fragmentada nacionalmente sin reemplazar la autoridad local.
El sistema recupera contenido relevante, genera una explicación y dirige a los usuarios a la fuente autorizada correcta — reduce la fricción mientras preserva la confianza.
 Ejemplo de un asistente de información pública en vivo usando generación aumentada por recuperación e inferencia privada basada en la UE.
Ejemplo de un asistente de información pública en vivo usando generación aumentada por recuperación e inferencia privada basada en la UE.
Por qué la ubicación de la inferencia importa para GDPR
Incluso cuando el contenido subyacente es público, el proceso de inferencia interpreta la intención del usuario y las consultas contextuales. Este procesamiento puede caer bajo consideraciones GDPR, lo que hace que la ubicación de la inferencia y las prácticas de manejo de datos sean críticas.
Ejecutar la inferencia dentro de la UE proporciona límites regulatorios más claros, gobernanza predecible y mayor transparencia tanto para los operadores como para los usuarios.
Resumen
La inferencia de IA privada basada en la UE hace posible combinar las capacidades modernas de IA con un manejo responsable de datos. Al emparejar la generación aumentada por recuperación con un runtime de inferencia controlado, los equipos pueden construir sistemas útiles y conformes sin sacrificar la usabilidad o el control.
Explora cómo reemplazar proveedores de inferencia externos con infraestructura basada en la UE funciona en la práctica, o aprende cómo los flujos de trabajo de automatización se integran con IA privada para cumplimiento de extremo a extremo.