GDPR-Compliant AI Applications: Private EU Inference with RAG (Architecture Guide)
Building AI applications that process user queries requires careful consideration of GDPR compliance requirements. Even when underlying data is public, user intent, search patterns, and interaction data constitute personal information subject to data protection regulations.
This guide provides a technical architecture for building GDPR-compliant AI applications using private EU-based inference combined with retrieval-augmented generation (RAG). The approach is designed for engineering teams and compliance professionals who need to implement AI capabilities while maintaining regulatory compliance.
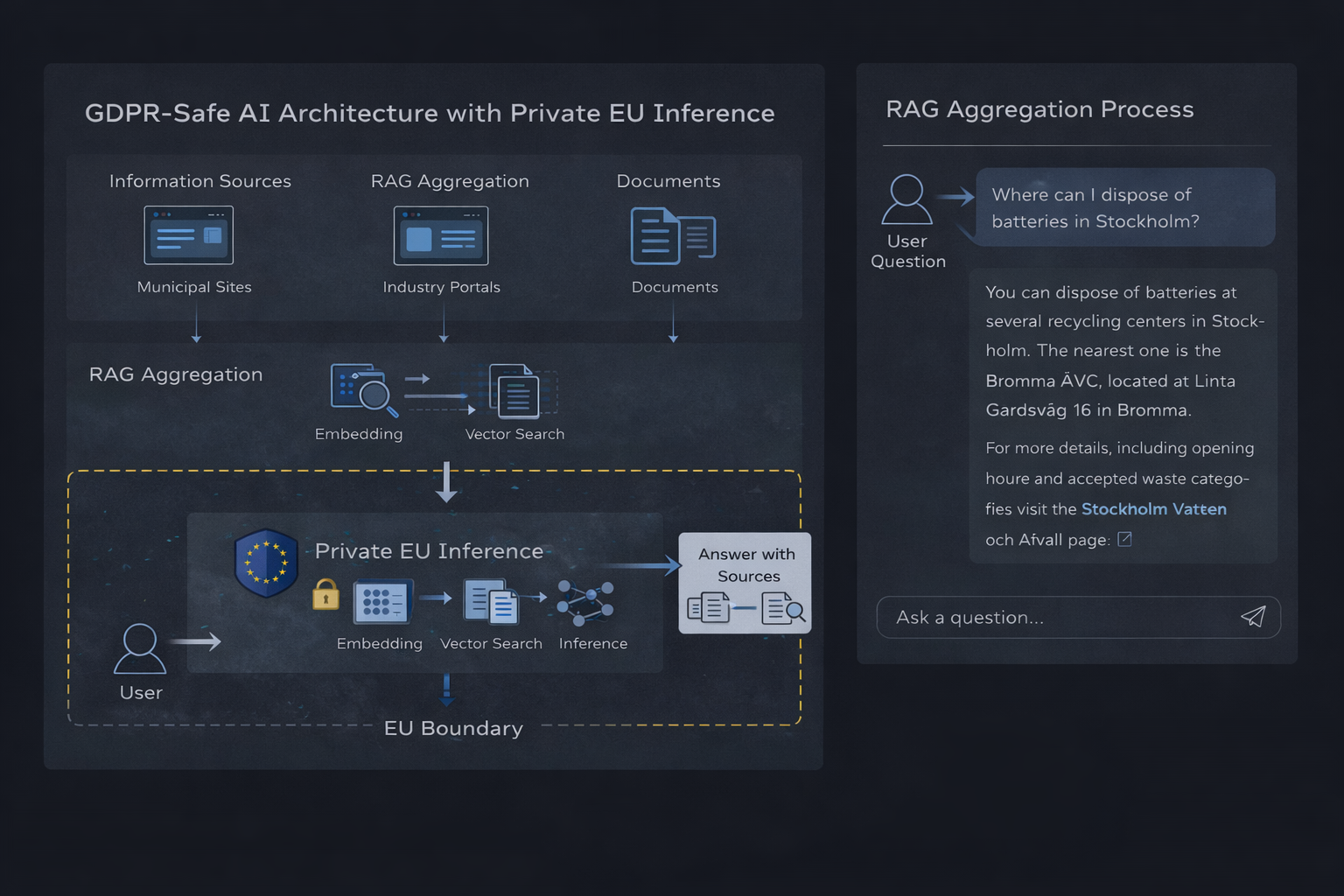 Private EU-based AI inference architecture with RAG aggregation
Private EU-based AI inference architecture with RAG aggregation
Quick Start
If you're already using OpenAI and just want to switch to GDPR-compliant EU hosting, here's how:
from openai import OpenAI
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explain GDPR Article 28 requirements."}]
)
print(response.choices[0].message.content)
That's it. No code changes beyond the base URL and API key. Your queries now process in EU infrastructure with contractual guarantees on data handling. See migration guide for details.
GDPR compliance requirements for AI inference
GDPR compliance for AI systems centers on three key principles: data minimization, purpose limitation, and territorial jurisdiction.
Data minimization requires processing only the data necessary for the specified purpose. In AI inference, this means avoiding the storage of user queries, conversation history, or derived insights beyond what's operationally required.
Purpose limitation restricts the use of processed data to the stated purpose. AI providers that use customer queries to improve models or train future versions violate this principle. Compliant systems must implement strict isolation between inference operations and any form of data retention or model training.
Territorial jurisdiction determines which regulatory framework applies. GDPR Article 3 establishes that processing of EU residents' data falls under EU jurisdiction regardless of where the organization is established. This makes the physical location of inference infrastructure a compliance requirement, not merely an architectural preference.
Private EU-based inference addresses these requirements by:
- Processing queries in real-time without persistent storage
- Isolating customer data from model training pipelines
- Operating inference infrastructure within EU territorial boundaries
- Providing contractual guarantees on data handling and processor relationships (Article 28)
Juicefactory.ai operates as a data processor under GDPR Article 28, with documented processing agreements and technical guarantees on data handling. No queries are retained, no data is used for training, and all processing occurs within EU infrastructure. See private inference runtime for details.
Why EU hosting matters for compliance
The physical location of AI inference infrastructure directly impacts regulatory compliance, data sovereignty, and legal enforceability.
Regulatory clarity: EU-hosted infrastructure operates under a single regulatory framework. When inference runs in the EU, data protection authorities have clear jurisdiction, processors operate under known legal requirements, and data subjects have enforceable rights under established procedures.
Data transfer avoidance: GDPR Chapter V imposes strict requirements on data transfers to third countries. EU-to-US data transfers require adequacy decisions, standard contractual clauses, or alternative mechanisms that create compliance overhead and legal uncertainty. Keeping inference within EU boundaries eliminates these transfer requirements entirely.
Processor accountability: Under GDPR Article 28, processors must demonstrate compliance through technical and organizational measures. EU-based processors operate under direct supervision of data protection authorities, are subject to the same breach notification requirements, and can be audited using established procedures.
Sovereignty and control: EU hosting ensures that legal processes, government requests, and data access follow EU procedures. Non-EU hosting may subject data to foreign legal frameworks, extraterritorial surveillance, or conflicting legal obligations.
The practical implication for AI systems is clear: EU hosting transforms compliance from an ongoing legal effort into an architectural guarantee.
RAG system architecture for GDPR compliance
Retrieval-augmented generation (RAG) combines information retrieval with language model inference to produce grounded, verifiable responses. The architecture consists of four distinct components, each with specific compliance considerations.
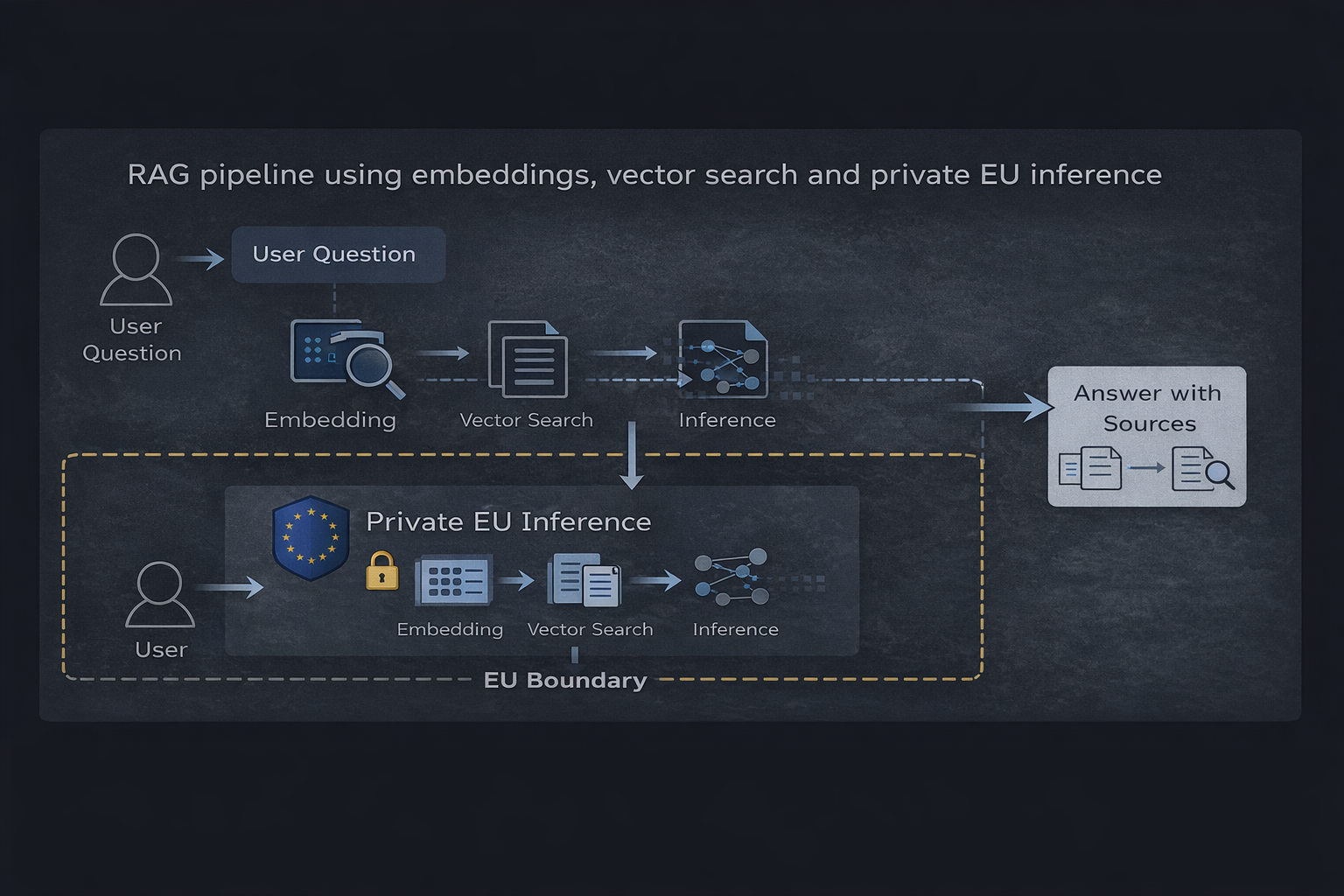 RAG pipeline using embeddings, vector search and private EU inference
RAG pipeline using embeddings, vector search and private EU inference
Architecture overview
1. Vector database stores embedded representations of source documents. The database itself contains derived data (embeddings) rather than raw user queries, making it suitable for persistent storage with appropriate access controls.
2. Embedding service converts user queries and documents into vector representations. This processing step must not retain query data or use it for training purposes.
3. Retrieval layer performs vector similarity search to identify relevant context. This component processes user queries transiently without persistent storage.
4. Inference runtime generates responses based on retrieved context. This is the critical compliance boundary — the runtime must process queries without storage, logging, or training data collection.
Data flow and compliance boundaries
- User submits a query (personal data under GDPR)
- Query is embedded without retention (transient processing)
- Vector search retrieves relevant context (no personal data involved)
- Context and query are sent to EU inference runtime
- Response is generated and returned (no storage of query or response)
- Optional: Response is logged by application layer (under customer control)
The key compliance feature of this architecture is isolation: personal data (user queries) flows through the system without persistence at the infrastructure level. Any data retention happens within the application layer under customer control, not at the service provider level.
For a practical implementation example, see our RAG with Python guide.
Vector database selection (Qdrant, pgvector, etc.)
Vector database selection impacts performance, operational complexity, and compliance posture. The primary options are specialized vector databases (Qdrant, Weaviate, Milvus), PostgreSQL extensions (pgvector), and managed services (Pinecone, AWS OpenSearch).
Qdrant
Qdrant is an open-source vector database designed specifically for similarity search. It supports HNSW indexing, filtered search, and distributed deployments.
Compliance advantages:
- Can be self-hosted in EU infrastructure
- No telemetry or phone-home requirements
- Clear data boundaries (only stores what you index)
- Suitable for air-gapped deployments
Operational characteristics:
- Requires dedicated infrastructure
- Built-in clustering for horizontal scaling
- gRPC and HTTP APIs for integration
pgvector
pgvector is a PostgreSQL extension that adds vector similarity search to existing PostgreSQL databases.
Compliance advantages:
- Leverages existing PostgreSQL infrastructure and compliance controls
- No additional external dependencies
- Data stays within established database boundaries
- Familiar operational model for teams already running PostgreSQL
Operational characteristics:
- Limited to approximate nearest neighbor search (HNSW, IVFFlat)
- Performance suitable for small to medium datasets (<10M vectors)
- Easy integration with existing application databases
Selection criteria for GDPR compliance
For GDPR-compliant architectures, the key decision factors are:
- Hosting control: Can the database be deployed in EU infrastructure?
- Data isolation: Does the database collect telemetry, usage data, or metadata beyond what you explicitly store?
- Operational expertise: Does your team have the capacity to operate the infrastructure?
Managed services (Pinecone, Weaviate Cloud) simplify operations but require careful evaluation of their data processing agreements and hosting locations. Self-hosted solutions (Qdrant, pgvector) provide maximum control but require operational capacity.
For most compliance-focused use cases, self-hosted Qdrant or pgvector in EU infrastructure provides the clearest compliance path. See our Qwen RAG guide for implementation examples.
Embedding models and privacy considerations
Embedding models convert text into vector representations for similarity search. The choice of embedding model and how it's operated directly impacts privacy and compliance.
Embedding model options
Cloud APIs (OpenAI embeddings, Cohere, Voyage) process text through external services. These services receive the full text of user queries and documents. Most cloud embedding providers explicitly reserve rights to use input data for model improvement, making them unsuitable for privacy-sensitive applications.
Self-hosted models (sentence-transformers, nomic-embed, bge-* models) run on your infrastructure and process data locally. These models provide full control over data flow and eliminate external data transfers.
Private API services like Juicefactory.ai provide embedding APIs with contractual guarantees on data handling. These services process embeddings without retention or training data collection, functioning as GDPR-compliant processors.
Privacy and compliance considerations
The critical compliance question for embeddings is: Does the embedding service see and retain user queries?
For document indexing, privacy concerns are minimal — the documents being embedded are typically not personal data, and indexing happens as a batch process under your control.
For query embeddings, privacy is critical. Each user query is processed by the embedding service. If that service retains queries, logs them, or uses them for training, it creates a compliance obligation and potential breach vector.
Compliant embedding architecture:
- Use self-hosted embedding models for maximum control
- If using an external embedding API, verify contractual guarantees on data handling
- Ensure embedding services operate as processors under GDPR Article 28
- Prefer EU-hosted services to avoid cross-border data transfers
Juicefactory.ai provides embedding APIs alongside inference services, with the same compliance guarantees: no data retention, no training data collection, EU hosting, and processor agreements. See API documentation for implementation details.
Private inference runtime setup
The inference runtime is the component that processes user queries and generates responses. This is the most critical compliance boundary in the architecture.
Compliance requirements for inference
A GDPR-compliant inference runtime must:
- Process queries without retention: Queries are processed in memory and discarded after response generation
- Isolate customer data from training: No query data, responses, or derived information is used to train or improve models
- Operate in EU jurisdiction: Infrastructure runs in EU data centers under EU legal frameworks
- Function as a processor: Service operates under GDPR Article 28 with documented processing agreements
- Provide audit capabilities: Customers can verify compliance through technical and contractual measures
Private inference vs. public APIs
Public AI APIs (OpenAI, Anthropic, Google) are designed for model development and improvement. Their terms of service typically grant broad rights to use customer data for training and quality improvement. Even when "opt-out" mechanisms exist, they require active configuration and may not apply to all processing activities.
Private inference services are architected for compliance. Data handling is contractually limited, infrastructure is dedicated or isolated, and the service operates as a processor rather than a controller.
Implementation with Juicefactory.ai
Juicefactory.ai provides private EU-based inference through an OpenAI-compatible API. The service supports:
- EU hosting: All inference runs in EU data centers
- No data retention: Queries and responses aren't stored
- No training data collection: Customer data is never used for model improvement
- Processor agreements: GDPR Article 28 compliant data processing agreements
- OpenAI API compatibility: Drop-in replacement for existing OpenAI integrations
Example implementation (modern OpenAI SDK v1.x+):
from openai import OpenAI
# Configure to use private EU inference
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
# Standard OpenAI API calls now route through private EU infrastructure
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain GDPR Article 28 requirements."}
]
)
print(response.choices[0].message.content)
No code changes are required beyond API endpoint configuration. Existing applications using OpenAI SDKs can switch to private inference by updating the base URL and API key.
See portal for deployment options and comparison guide for feature analysis.
Framework Integration
Modern AI frameworks work seamlessly with OpenAI-compatible endpoints. Here's how to integrate with popular tools:
LangChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.invoke("Explain GDPR data minimization principle")
print(response.content)
LlamaIndex
from llama_index.llms.openai import OpenAI
llm = OpenAI(
api_base="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.complete("Explain GDPR data minimization principle")
print(response.text)
curl (direct API)
curl https://api.juicefactory.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jf_your_key_here" \
-d '{
"model": "gpt-4",
"messages": [{"role": "user", "content": "Explain GDPR Article 28"}]
}'
All frameworks that support OpenAI's API work without modification — just point them to the EU-based endpoint. For more integration examples, see our stateless LLM API guide.
Why single-GPU high-memory inference matters for compliance
Infrastructure architecture directly impacts GDPR compliance guarantees. Single-GPU high-memory inference provides isolation properties that distributed systems can't match.
The compliance challenge of model sharding
Large language models often exceed single-GPU memory capacity, forcing deployment across multiple GPUs or nodes. This distribution creates data protection vulnerabilities:
Cross-node leakage risk: When a model's sharded across multiple GPUs or servers, query data flows through multiple memory spaces. Each boundary represents a potential leakage point. Debugging tools, memory dumps, or system failures can expose query fragments across infrastructure.
Increased attack surface: Each additional node multiplies the attack surface. Memory side-channel attacks (Spectre, Meltdown variants) become more effective when query data's distributed across shared infrastructure.
Single-GPU advantages for GDPR compliance
High-memory GPUs (96GB, 128GB, or larger) can host large models (70B parameters, GPT-4 class) within a single memory space. This architectural simplification provides compliance benefits:
Predictable isolation: All inference occurs within a single GPU's memory. Query data never crosses memory boundaries, network interfaces, or inter-process communication channels. The data path is deterministic and auditable.
Atomic processing: Each query enters GPU memory, undergoes inference, produces a response, and is discarded — entirely within silicon boundaries. No intermediate storage, no cross-node coordination, no residual data in system memory.
Reduced blast radius: Security incidents are contained to a single GPU. Memory compromises can't propagate across infrastructure, limiting exposure scope.
JuiceFactory infrastructure model
JuiceFactory AI operates inference on dedicated high-memory GPUs (96GB+) running single-model instances:
- No model sharding: Each GPU hosts a complete model in its own memory
- No multi-tenancy at GPU level: Customer queries don't share GPU memory space
- Ephemeral processing: GPU memory is cleared between requests
- Single-region processing: Queries never traverse other regions
| Architecture | Memory efficiency | Compliance auditability | Isolation guarantees |
|---|---|---|---|
| Distributed (4x24GB) | High | Complex | Probabilistic |
| Single GPU (96GB) | Moderate | Straightforward | Deterministic |
For GDPR-critical applications, the single-GPU model provides the clearest compliance path.
Real-world example: Public information assistant
Public information systems present a clear use case for GDPR-compliant AI: even when underlying data is public, user queries reveal intent, interests, and information needs that constitute personal data.
Architecture: Swedish company information assistant
A real-world implementation of this architecture can be seen in a public information assistant for Swedish companies. The system aggregates company information from multiple authoritative sources (Bolagsverket, tax authority, industry registries) and provides a natural language interface for queries.
Data characteristics:
- All source data is public (company registrations, financial reports, public records)
- User queries reveal business interests, competitive research, and investigative intent
- System serves both Swedish and EU users
Technical implementation:
- Document indexing: Public company data indexed in self-hosted Qdrant instance
- Embeddings: Documents and queries embedded using EU-hosted embedding service
- Retrieval: Vector similarity search identifies relevant company information
- Inference: Juicefactory.ai private EU inference generates natural language responses
- Response: Answer returned with citations to authoritative sources
Compliance posture:
- User queries processed without retention (transient processing under GDPR Article 6(1)(f))
- All processing infrastructure located in EU
- No data transfers to third countries
- Service operates as data processor with documented agreements
This architecture demonstrates that GDPR compliance doesn't require sacrificing functionality. The system provides modern AI capabilities while maintaining strict data handling boundaries.
 Example of a live public-information assistant using retrieval-augmented generation and private EU-based inference.
Example of a live public-information assistant using retrieval-augmented generation and private EU-based inference.
Summary and next steps
GDPR-compliant AI applications require architectural decisions at every layer: vector databases must be deployed with control over data location, embedding models must process queries without retention, and inference runtimes must operate as compliant processors under EU jurisdiction.
The RAG architecture presented in this guide provides a practical implementation path:
- Vector database: Self-hosted Qdrant or pgvector in EU infrastructure
- Embeddings: Self-hosted models or EU-based API services with processor agreements
- Inference: Private EU runtime with contractual guarantees on data handling
- Application layer: Customer-controlled logging and data retention policies
This architecture shifts compliance from ongoing legal effort to structural guarantee. By choosing infrastructure that can't violate GDPR requirements, engineering teams can build AI applications without continuous compliance overhead.
Implementation resources
- Get started: Create API key for private EU inference
- Migration: Migrate from OpenAI with step-by-step instructions
- Comparison: EU LLM API comparison for provider evaluation
- Pricing: Deployment options for production use
Frequently Asked Questions
Does GDPR apply if I only process public data?
GDPR applies based on the processing of personal data, not the source data. Even when underlying information is public, user queries, search patterns, and interaction logs constitute personal data under GDPR Article 4(1). If your system processes queries from EU residents, GDPR applies regardless of whether the answers come from public sources.
Is EU hosting legally required for GDPR compliance?
EU hosting isn't strictly required — GDPR permits data transfers to third countries under Chapter V mechanisms (adequacy decisions, standard contractual clauses, binding corporate rules). However, these mechanisms create compliance overhead, legal uncertainty, and operational complexity. EU hosting eliminates transfer requirements entirely, providing a simpler and more robust compliance path.
How do RAG systems reduce compliance risk compared to fine-tuned models?
RAG systems separate data storage (vector database) from model inference (LLM runtime). User data influences response generation through retrieval context, but doesn't modify model weights. This architectural separation makes it possible to control data retention, audit data flows, and implement compliant processing. Fine-tuned models, by contrast, incorporate training data into model weights, making it difficult to delete specific data points or audit data influence.
What's the difference between a data processor and data controller for AI services?
Under GDPR Article 4, a controller determines the purposes and means of processing, while a processor processes data on behalf of the controller. For AI services, you (the application developer) are typically the controller, and the AI service provider is the processor. This distinction matters because processors operate under your instructions and must sign data processing agreements (Article 28) limiting their use of data. Private inference services function as processors; public AI APIs often function as controllers or claim joint controller status.
Can I use this architecture for internal employee-facing applications?
Yes. GDPR applies to employee data with the same rigor as customer data. Internal AI applications that process employee queries, HR information, or business documents require the same compliance measures. The architecture described in this guide applies equally to internal and external applications.
Does JuiceFactory store user prompts?
No. JuiceFactory AI operates as a stateless inference service and doesn't store user prompts, responses, or any query-derived data. This is a contractual guarantee under GDPR Article 28 data processing agreements, not merely a policy statement. Prompts are processed in GPU memory and discarded after response generation. Operational logs contain request metadata (timestamp, request ID, model version, latency, token count) but not prompt content or responses.
What models are available through EU-hosted inference?
JuiceFactory AI provides access to frontier models including GPT-4 class, Claude, and Llama-3-70B through EU infrastructure. Model availability changes regularly as new releases become available. See API documentation for the current model catalog.
How does pricing compare to OpenAI?
Private EU inference typically costs 1.5-2x public API pricing due to dedicated infrastructure and compliance overhead. For organizations spending less than EUR 1,000/month on AI, public APIs may be more cost-effective. For enterprise deployments (EUR 10k+/month), the compliance benefits justify the premium. See portal for detailed rates.
Does LangChain support EU-hosted inference?
Yes. LangChain and other OpenAI-compatible frameworks work seamlessly with EU-hosted endpoints. See the Framework Integration section above for examples. Any framework supporting OpenAI's API can use EU-hosted inference without modification.
How can I monitor and observe inference requests?
JuiceFactory AI provides standard API response headers including processing time, region, and token usage. For application-level monitoring, you'll need to implement logging in your application layer. Operational metrics (latency, error rates, token consumption) can be tracked through your API dashboard. Since queries aren't retained at the infrastructure level, query-level analytics must be implemented in your application if needed.
Is stateless inference truly GDPR compliant?
Stateless inference — where queries are processed in memory without persistent storage — satisfies GDPR data minimization requirements (Article 5(1)(c)) when implemented correctly. The compliance depends on three technical guarantees: no query logging, proper memory lifecycle management, and no derivative retention. JuiceFactory AI implements stateless processing with these guarantees, allowing organizations to invoke inference under GDPR Article 6(1)(f) (legitimate interest) for transient processing. Organizations can verify stateless processing through infrastructure audits, network analysis, and Article 28 audit rights.
Related guides
- RAG with Python: GDPR Document Search - Practical implementation of vector search with EU inference
- RAG with Qwen: EU-Hosted Embeddings - Using Qwen models for GDPR-compliant RAG
- Stateless LLM API for GDPR - Deep dive on stateless processing architecture
- EU LLM API Comparison - Compare EU-hosted AI providers
- Migrate from OpenAI to EU API - Step-by-step migration guide