DSGVO-konforme KI-Anwendungen: Private EU-Inferenz mit RAG (Architektur-Leitfaden)
Die Entwicklung von KI-Anwendungen, die Benutzeranfragen verarbeiten, erfordert eine sorgfaeltige Beruecksichtigung der DSGVO-Compliance-Anforderungen. Selbst wenn die zugrundeliegenden Daten oeffentlich sind, stellen Benutzerabsichten, Suchmuster und Interaktionsdaten personenbezogene Informationen dar, die den Datenschutzvorschriften unterliegen.
Dieser Leitfaden beschreibt eine technische Architektur fuer den Aufbau DSGVO-konformer KI-Anwendungen unter Verwendung privater, EU-basierter Inferenz in Kombination mit Retrieval-Augmented Generation (RAG). Der Ansatz richtet sich an Entwicklungsteams und Compliance-Verantwortliche, die KI-Funktionen implementieren und gleichzeitig die regulatorische Konformitaet sicherstellen muessen.
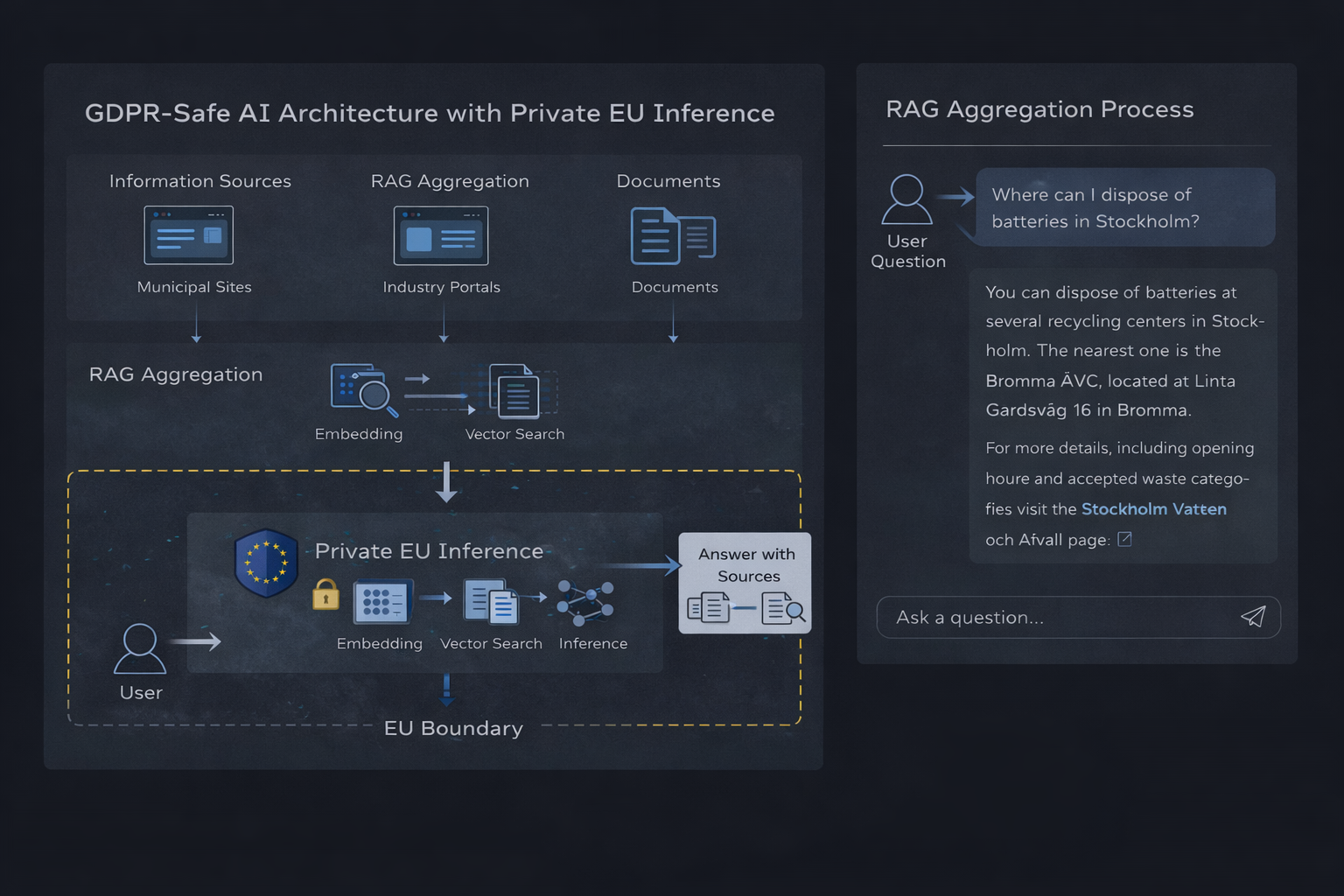 Private EU-basierte KI-Inferenz-Architektur mit RAG-Aggregation
Private EU-basierte KI-Inferenz-Architektur mit RAG-Aggregation
Schnellstart
Falls Sie bereits OpenAI nutzen und lediglich auf DSGVO-konforme EU-Infrastruktur umsteigen moechten, genuegt Folgendes:
from openai import OpenAI
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explain GDPR Article 28 requirements."}]
)
print(response.choices[0].message.content)
Das war's. Ausser der Base-URL und dem API-Key sind keine Code-Aenderungen erforderlich. Ihre Anfragen werden ab sofort ueber EU-Infrastruktur verarbeitet, mit vertraglichen Garantien zur Datenverarbeitung. Details finden Sie im Migrationsleitfaden.
DSGVO-Compliance-Anforderungen fuer KI-Inferenz
Die DSGVO-Konformitaet fuer KI-Systeme basiert auf drei zentralen Grundsaetzen: Datenminimierung, Zweckbindung und territoriale Zustaendigkeit.
Datenminimierung verlangt, dass nur die Daten verarbeitet werden, die fuer den angegebenen Zweck erforderlich sind. Bei der KI-Inferenz bedeutet dies, dass Benutzeranfragen, Gespraechsverlaeufe oder abgeleitete Erkenntnisse nicht ueber das betrieblich Notwendige hinaus gespeichert werden duerfen.
Zweckbindung beschraenkt die Verwendung verarbeiteter Daten auf den angegebenen Zweck. KI-Anbieter, die Kundenanfragen zur Modellverbesserung oder zum Training kuenftiger Versionen verwenden, verstossen gegen diesen Grundsatz. Konforme Systeme muessen eine strikte Trennung zwischen Inferenz-Operationen und jeglicher Form der Datenspeicherung oder des Modelltrainings gewaehrleisten.
Territoriale Zustaendigkeit bestimmt, welcher Rechtsrahmen gilt. Artikel 3 DSGVO legt fest, dass die Verarbeitung von Daten in der EU ansaessiger Personen unter EU-Recht faellt -- unabhaengig davon, wo die verarbeitende Organisation ihren Sitz hat. Damit wird der physische Standort der Inferenz-Infrastruktur zu einer Compliance-Anforderung, nicht bloss zu einer architektonischen Praeferenz.
Private EU-basierte Inferenz adressiert diese Anforderungen durch:
- Echtzeitverarbeitung von Anfragen ohne persistente Speicherung
- Isolierung von Kundendaten gegenueber Modelltraining-Pipelines
- Betrieb der Inferenz-Infrastruktur innerhalb der EU-Grenzen
- Vertragliche Garantien zur Datenverarbeitung und Auftragsverarbeiter-Beziehungen (Artikel 28 DSGVO)
Juicefactory.ai agiert als Auftragsverarbeiter gemaess Artikel 28 DSGVO, mit dokumentierten Auftragsverarbeitungsvertraegen und technischen Garantien zur Datenverarbeitung. Anfragen werden nicht gespeichert, Daten werden nicht fuer Training verwendet, und die gesamte Verarbeitung findet innerhalb der EU-Infrastruktur statt. Details finden Sie unter Private Inferenz-Laufzeitumgebung.
Warum EU-Hosting fuer Compliance entscheidend ist
Der physische Standort der KI-Inferenz-Infrastruktur hat unmittelbare Auswirkungen auf die regulatorische Konformitaet, die Datensouveraenitaet und die rechtliche Durchsetzbarkeit.
Regulatorische Klarheit: EU-gehostete Infrastruktur operiert unter einem einheitlichen Rechtsrahmen. Wenn die Inferenz in der EU laeuft, haben Datenschutzbehoerden eine klare Zustaendigkeit, Auftragsverarbeiter agieren unter bekannten rechtlichen Anforderungen, und betroffene Personen koennen ihre Rechte ueber etablierte Verfahren durchsetzen.
Vermeidung von Datentransfers: Kapitel V der DSGVO stellt strenge Anforderungen an Datentransfers in Drittstaaten. EU-US-Datentransfers erfordern Angemessenheitsbeschluesse, Standardvertragsklauseln oder alternative Mechanismen, die Compliance-Aufwand und rechtliche Unsicherheit erzeugen. Die Verarbeitung innerhalb der EU-Grenzen eliminiert diese Transferanforderungen vollstaendig.
Verantwortlichkeit des Auftragsverarbeiters: Gemaess Artikel 28 DSGVO muessen Auftragsverarbeiter die Einhaltung durch technische und organisatorische Massnahmen nachweisen. EU-basierte Auftragsverarbeiter unterliegen der direkten Aufsicht der Datenschutzbehoerden, den gleichen Meldepflichten bei Datenschutzverletzungen und koennen mit etablierten Verfahren geprueft werden.
Souveraenitaet und Kontrolle: EU-Hosting stellt sicher, dass rechtliche Verfahren, Behoerdenanfragen und Datenzugriffe den EU-Verfahren folgen. Nicht-EU-Hosting kann Daten auslaendischen Rechtsrahmen, extraterritorialer Ueberwachung oder kollidierenden Rechtspflichten aussetzen.
Die praktische Konsequenz fuer KI-Systeme ist klar: EU-Hosting verwandelt Compliance von einer laufenden rechtlichen Aufgabe in eine architektonische Garantie.
RAG-Systemarchitektur fuer DSGVO-Konformitaet
Retrieval-Augmented Generation (RAG) kombiniert Informationsabruf mit Sprachmodell-Inferenz, um fundierte, nachpruefbare Antworten zu erzeugen. Die Architektur besteht aus vier separaten Komponenten, die jeweils spezifische Compliance-Anforderungen mit sich bringen.
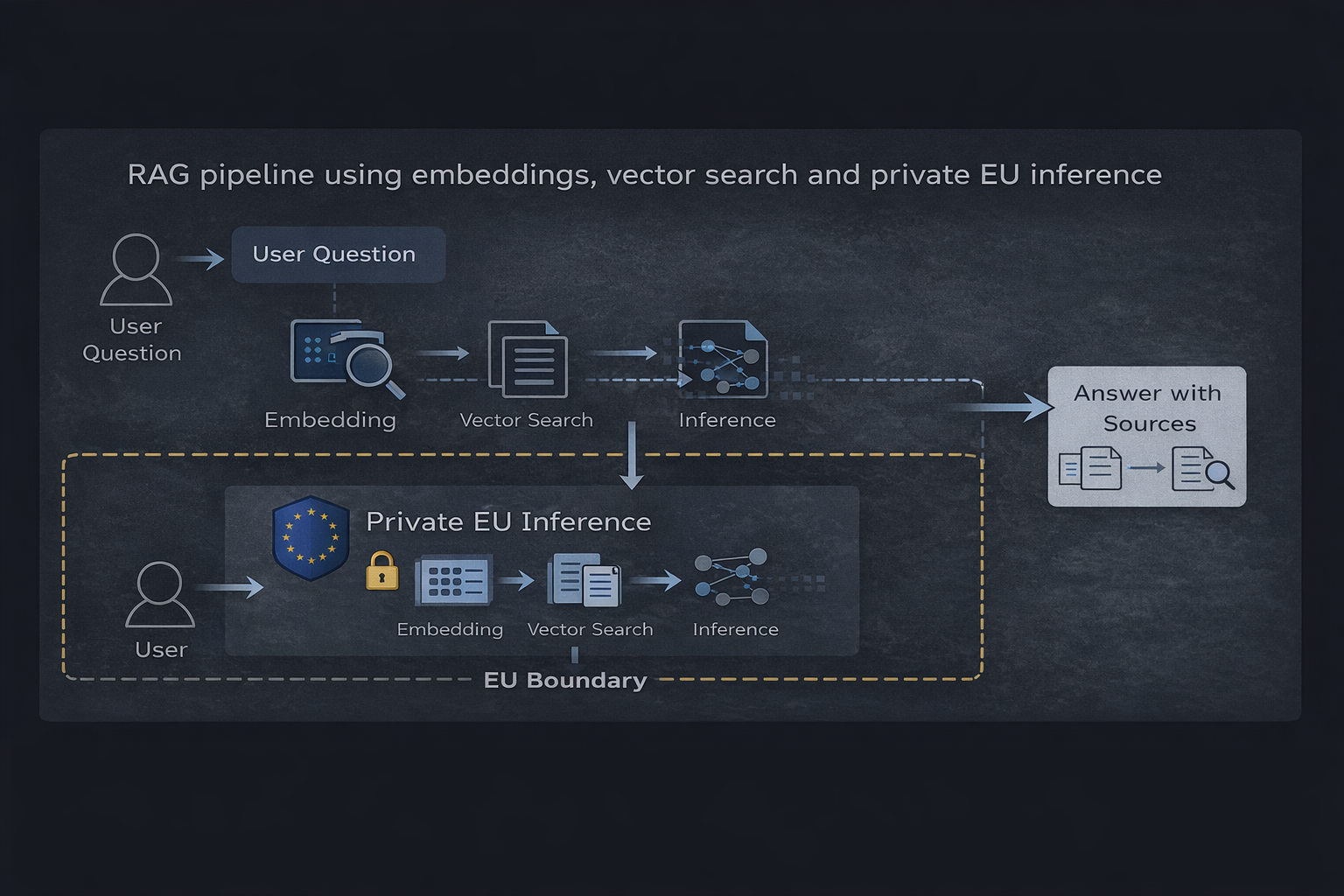 RAG-Pipeline mit Embeddings, Vektorsuche und privater EU-Inferenz
RAG-Pipeline mit Embeddings, Vektorsuche und privater EU-Inferenz
Architektur-Uebersicht
1. Vektordatenbank speichert eingebettete Repraesentationen von Quelldokumenten. Die Datenbank selbst enthaelt abgeleitete Daten (Embeddings) statt roher Benutzeranfragen, was sie fuer die persistente Speicherung mit geeigneten Zugriffskontrollen qualifiziert.
2. Embedding-Service wandelt Benutzeranfragen und Dokumente in Vektor-Repraesentationen um. Dieser Verarbeitungsschritt darf keine Anfragedaten speichern oder fuer Trainingszwecke verwenden.
3. Abrufschicht fuehrt eine Vektoraehnlichkeitssuche durch, um relevanten Kontext zu identifizieren. Diese Komponente verarbeitet Benutzeranfragen transient, ohne persistente Speicherung.
4. Inferenz-Laufzeitumgebung generiert Antworten auf Basis des abgerufenen Kontexts. Dies ist die kritische Compliance-Grenze -- die Laufzeitumgebung muss Anfragen ohne Speicherung, Protokollierung oder Sammlung von Trainingsdaten verarbeiten.
Datenfluss und Compliance-Grenzen
- Benutzer stellt eine Anfrage (personenbezogene Daten gemaess DSGVO)
- Anfrage wird ohne Speicherung eingebettet (transiente Verarbeitung)
- Vektorsuche ruft relevanten Kontext ab (keine personenbezogenen Daten beteiligt)
- Kontext und Anfrage werden an die EU-Inferenz-Laufzeitumgebung gesendet
- Antwort wird generiert und zurueckgegeben (keine Speicherung von Anfrage oder Antwort)
- Optional: Antwort wird durch die Anwendungsschicht protokolliert (unter Kontrolle des Kunden)
Das zentrale Compliance-Merkmal dieser Architektur ist die Isolation: Personenbezogene Daten (Benutzeranfragen) fliessen durch das System, ohne auf Infrastrukturebene persistent gespeichert zu werden. Jegliche Datenspeicherung findet innerhalb der Anwendungsschicht unter Kontrolle des Kunden statt, nicht auf Ebene des Dienstleisters.
Ein praktisches Implementierungsbeispiel finden Sie in unserem RAG-mit-Python-Leitfaden.
Auswahl der Vektordatenbank (Qdrant, pgvector u.a.)
Die Wahl der Vektordatenbank beeinflusst Performance, betriebliche Komplexitaet und Compliance-Positionierung. Die wichtigsten Optionen sind spezialisierte Vektordatenbanken (Qdrant, Weaviate, Milvus), PostgreSQL-Erweiterungen (pgvector) und verwaltete Dienste (Pinecone, AWS OpenSearch).
Qdrant
Qdrant ist eine Open-Source-Vektordatenbank, die speziell fuer Aehnlichkeitssuche entwickelt wurde. Sie unterstuetzt HNSW-Indexierung, gefilterte Suche und verteilte Deployments.
Compliance-Vorteile:
- Kann in EU-Infrastruktur selbst gehostet werden
- Keine Telemetrie oder Phone-Home-Anforderungen
- Klare Datengrenzen (speichert nur, was Sie indexieren)
- Geeignet fuer Air-Gap-Deployments
Betriebliche Eigenschaften:
- Erfordert dedizierte Infrastruktur
- Integriertes Clustering fuer horizontale Skalierung
- gRPC- und HTTP-APIs fuer die Integration
pgvector
pgvector ist eine PostgreSQL-Erweiterung, die Vektoraehnlichkeitssuche zu bestehenden PostgreSQL-Datenbanken hinzufuegt.
Compliance-Vorteile:
- Nutzt bestehende PostgreSQL-Infrastruktur und Compliance-Kontrollen
- Keine zusaetzlichen externen Abhaengigkeiten
- Daten verbleiben innerhalb etablierter Datenbankgrenzen
- Vertrautes Betriebsmodell fuer Teams, die bereits PostgreSQL betreiben
Betriebliche Eigenschaften:
- Beschraenkt auf approximative Naechster-Nachbar-Suche (HNSW, IVFFlat)
- Performance geeignet fuer kleine bis mittlere Datensaetze (<10M Vektoren)
- Einfache Integration mit bestehenden Anwendungsdatenbanken
Auswahlkriterien fuer DSGVO-Konformitaet
Fuer DSGVO-konforme Architekturen sind die zentralen Entscheidungsfaktoren:
- Hosting-Kontrolle: Kann die Datenbank in EU-Infrastruktur betrieben werden?
- Datenisolation: Sammelt die Datenbank Telemetrie, Nutzungsdaten oder Metadaten ueber das hinaus, was Sie explizit speichern?
- Betriebliche Expertise: Verfuegt Ihr Team ueber die Kapazitaet, die Infrastruktur zu betreiben?
Verwaltete Dienste (Pinecone, Weaviate Cloud) vereinfachen den Betrieb, erfordern aber eine sorgfaeltige Bewertung ihrer Auftragsverarbeitungsvertraege und Hosting-Standorte. Selbst gehostete Loesungen (Qdrant, pgvector) bieten maximale Kontrolle, erfordern aber betriebliche Kapazitaet.
Fuer die meisten Compliance-orientierten Anwendungsfaelle bietet selbst gehostetes Qdrant oder pgvector in EU-Infrastruktur den klarsten Compliance-Pfad. Implementierungsbeispiele finden Sie in unserem Qwen-RAG-Leitfaden.
Embedding-Modelle und Datenschutzaspekte
Embedding-Modelle wandeln Text in Vektor-Repraesentationen fuer die Aehnlichkeitssuche um. Die Wahl des Embedding-Modells und dessen Betrieb haben unmittelbaren Einfluss auf Datenschutz und Compliance.
Embedding-Modell-Optionen
Cloud-APIs (OpenAI Embeddings, Cohere, Voyage) verarbeiten Text ueber externe Dienste. Diese Dienste erhalten den vollstaendigen Text der Benutzeranfragen und Dokumente. Die meisten Cloud-Embedding-Anbieter behalten sich ausdruecklich das Recht vor, Eingabedaten zur Modellverbesserung zu nutzen, was sie fuer datenschutzsensible Anwendungen ungeeignet macht.
Selbst gehostete Modelle (sentence-transformers, nomic-embed, bge-*-Modelle) laufen auf Ihrer eigenen Infrastruktur und verarbeiten Daten lokal. Diese Modelle bieten vollstaendige Kontrolle ueber den Datenfluss und eliminieren externe Datentransfers.
Private API-Dienste wie Juicefactory.ai bieten Embedding-APIs mit vertraglichen Garantien zur Datenverarbeitung. Diese Dienste verarbeiten Embeddings ohne Speicherung oder Sammlung von Trainingsdaten und fungieren als DSGVO-konforme Auftragsverarbeiter.
Datenschutz und Compliance-Aspekte
Die zentrale Compliance-Frage bei Embeddings lautet: Sieht und speichert der Embedding-Service Benutzeranfragen?
Bei der Dokumentenindexierung sind Datenschutzbedenken minimal -- die eingebetteten Dokumente sind in der Regel keine personenbezogenen Daten, und die Indexierung erfolgt als Batch-Prozess unter Ihrer Kontrolle.
Bei Query-Embeddings ist der Datenschutz kritisch. Jede Benutzeranfrage wird durch den Embedding-Service verarbeitet. Wenn dieser Dienst Anfragen speichert, protokolliert oder fuer Training verwendet, entsteht eine Compliance-Verpflichtung und ein potenzielles Datenschutzrisiko.
Konforme Embedding-Architektur:
- Verwenden Sie selbst gehostete Embedding-Modelle fuer maximale Kontrolle
- Bei Nutzung einer externen Embedding-API: Pruefen Sie die vertraglichen Garantien zur Datenverarbeitung
- Stellen Sie sicher, dass Embedding-Dienste als Auftragsverarbeiter gemaess Artikel 28 DSGVO agieren
- Bevorzugen Sie EU-gehostete Dienste, um grenzueberschreitende Datentransfers zu vermeiden
Juicefactory.ai bietet Embedding-APIs neben Inferenz-Diensten mit denselben Compliance-Garantien: keine Datenspeicherung, keine Sammlung von Trainingsdaten, EU-Hosting und Auftragsverarbeitungsvertraege. Details finden Sie in der API-Dokumentation.
Einrichtung der privaten Inferenz-Laufzeitumgebung
Die Inferenz-Laufzeitumgebung ist die Komponente, die Benutzeranfragen verarbeitet und Antworten generiert. Sie stellt die kritischste Compliance-Grenze in der Architektur dar.
Compliance-Anforderungen an die Inferenz
Eine DSGVO-konforme Inferenz-Laufzeitumgebung muss:
- Anfragen ohne Speicherung verarbeiten: Anfragen werden im Arbeitsspeicher verarbeitet und nach der Antwortgenerierung verworfen
- Kundendaten vom Training isolieren: Keine Anfragedaten, Antworten oder abgeleiteten Informationen werden zur Modellverbesserung verwendet
- In EU-Jurisdiktion operieren: Die Infrastruktur laeuft in EU-Rechenzentren unter EU-Rechtsrahmen
- Als Auftragsverarbeiter fungieren: Der Dienst operiert gemaess Artikel 28 DSGVO mit dokumentierten Auftragsverarbeitungsvertraegen
- Pruefmoeglichkeiten bieten: Kunden koennen die Einhaltung durch technische und vertragliche Massnahmen verifizieren
Private Inferenz vs. oeffentliche APIs
Oeffentliche KI-APIs (OpenAI, Anthropic, Google) sind auf Modellentwicklung und -verbesserung ausgelegt. Ihre Nutzungsbedingungen raeumen in der Regel weitreichende Rechte zur Verwendung von Kundendaten fuer Training und Qualitaetsverbesserung ein. Selbst wenn Opt-out-Mechanismen vorhanden sind, erfordern diese eine aktive Konfiguration und gelten moeglicherweise nicht fuer alle Verarbeitungstaetigkeiten.
Private Inferenz-Dienste sind auf Compliance ausgerichtet. Die Datenverarbeitung ist vertraglich eingeschraenkt, die Infrastruktur ist dediziert oder isoliert, und der Dienst agiert als Auftragsverarbeiter statt als Verantwortlicher.
Implementierung mit Juicefactory.ai
Juicefactory.ai bietet private EU-basierte Inferenz ueber eine OpenAI-kompatible API. Der Dienst unterstuetzt:
- EU-Hosting: Alle Inferenz laeuft in EU-Rechenzentren
- Keine Datenspeicherung: Anfragen und Antworten werden nicht gespeichert
- Keine Sammlung von Trainingsdaten: Kundendaten werden niemals zur Modellverbesserung verwendet
- Auftragsverarbeitungsvertraege: DSGVO-konforme Auftragsverarbeitungsvertraege gemaess Artikel 28
- OpenAI-API-Kompatibilitaet: Drop-in-Ersatz fuer bestehende OpenAI-Integrationen
Beispiel-Implementierung (modernes OpenAI SDK v1.x+):
from openai import OpenAI
# Konfiguration fuer private EU-Inferenz
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
# Standard-OpenAI-API-Aufrufe laufen jetzt ueber private EU-Infrastruktur
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain GDPR Article 28 requirements."}
]
)
print(response.choices[0].message.content)
Ueber die API-Endpunkt-Konfiguration hinaus sind keine Code-Aenderungen erforderlich. Bestehende Anwendungen, die OpenAI-SDKs verwenden, koennen durch Aktualisierung der Base-URL und des API-Keys auf private Inferenz umsteigen.
Details zu Deployment-Optionen finden Sie im Portal, eine Feature-Analyse im Vergleichsleitfaden.
Framework-Integration
Moderne KI-Frameworks funktionieren nahtlos mit OpenAI-kompatiblen Endpunkten. So integrieren Sie die gaengigsten Tools:
LangChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.invoke("Explain GDPR data minimization principle")
print(response.content)
LlamaIndex
from llama_index.llms.openai import OpenAI
llm = OpenAI(
api_base="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.complete("Explain GDPR data minimization principle")
print(response.text)
curl (direkte API)
curl https://api.juicefactory.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jf_your_key_here" \
-d '{
"model": "gpt-4",
"messages": [{"role": "user", "content": "Explain GDPR Article 28"}]
}'
Alle Frameworks, die OpenAIs API unterstuetzen, funktionieren ohne Modifikation -- zeigen Sie sie einfach auf den EU-basierten Endpunkt. Weitere Integrationsbeispiele finden Sie in unserem Leitfaden zur zustandslosen LLM-API.
Warum Single-GPU-Inferenz mit viel Arbeitsspeicher fuer Compliance relevant ist
Die Infrastruktur-Architektur hat unmittelbaren Einfluss auf die DSGVO-Compliance-Garantien. Single-GPU-Inferenz mit hohem Arbeitsspeicher bietet Isolationseigenschaften, die verteilte Systeme nicht erreichen koennen.
Die Compliance-Herausforderung bei Model-Sharding
Grosse Sprachmodelle ueberschreiten haeufig die Speicherkapazitaet einer einzelnen GPU, was ein Deployment ueber mehrere GPUs oder Knoten erzwingt. Diese Verteilung erzeugt Datenschutz-Schwachstellen:
Risiko von knotenuebergreifendem Datenleck: Wenn ein Modell ueber mehrere GPUs oder Server verteilt wird, fliessen Anfragedaten durch mehrere Speicherbereiche. Jede Grenze stellt einen potenziellen Leckpunkt dar. Debugging-Tools, Speicherabbilder oder Systemausfaelle koennen Anfragefragmente ueber die gesamte Infrastruktur offenlegen.
Vergroesserte Angriffsflaeche: Jeder zusaetzliche Knoten vervielfacht die Angriffsflaeche. Seitenkanalangriffe auf den Arbeitsspeicher (Spectre-, Meltdown-Varianten) werden effektiver, wenn Anfragedaten ueber gemeinsam genutzte Infrastruktur verteilt sind.
Single-GPU-Vorteile fuer DSGVO-Konformitaet
GPUs mit grossem Arbeitsspeicher (96 GB, 128 GB oder mehr) koennen grosse Modelle (70B Parameter, GPT-4-Klasse) in einem einzigen Speicherbereich hosten. Diese architektonische Vereinfachung bietet Compliance-Vorteile:
Vorhersagbare Isolation: Die gesamte Inferenz erfolgt im Speicher einer einzelnen GPU. Anfragedaten ueberschreiten keine Speichergrenzen, Netzwerkschnittstellen oder Interprozesskommunikationskanaele. Der Datenpfad ist deterministisch und pruefbar.
Atomare Verarbeitung: Jede Anfrage gelangt in den GPU-Speicher, durchlaeuft die Inferenz, erzeugt eine Antwort und wird verworfen -- vollstaendig innerhalb der Silizium-Grenzen. Kein Zwischenspeicher, keine knotenuebergreifende Koordination, keine Restdaten im Systemspeicher.
Begrenzter Schadensradius: Sicherheitsvorfaelle sind auf eine einzelne GPU beschraenkt. Speicherkompromittierungen koennen sich nicht ueber die Infrastruktur ausbreiten, was den Umfang der Exposition begrenzt.
JuiceFactory-Infrastrukturmodell
JuiceFactory AI betreibt Inferenz auf dedizierten GPUs mit grossem Arbeitsspeicher (96 GB+) und Single-Model-Instanzen:
- Kein Model-Sharding: Jede GPU hostet ein vollstaendiges Modell in ihrem eigenen Speicher
- Keine Multi-Tenancy auf GPU-Ebene: Kundenanfragen teilen sich keinen GPU-Speicherbereich
- Ephemere Verarbeitung: Der GPU-Speicher wird zwischen Anfragen geloescht
- Single-Region-Verarbeitung: Anfragen durchqueren niemals andere Regionen
| Architektur | Speichereffizienz | Compliance-Pruefbarkeit | Isolationsgarantien |
|---|---|---|---|
| Verteilt (4x24 GB) | Hoch | Komplex | Probabilistisch |
| Single GPU (96 GB) | Moderat | Unkompliziert | Deterministisch |
Fuer DSGVO-kritische Anwendungen bietet das Single-GPU-Modell den klarsten Compliance-Pfad.
Praxisbeispiel: Assistent fuer oeffentliche Informationen
Systeme fuer oeffentliche Informationen stellen einen klaren Anwendungsfall fuer DSGVO-konforme KI dar: Selbst wenn die zugrundeliegenden Daten oeffentlich sind, offenbaren Benutzeranfragen Absichten, Interessen und Informationsbeduerfnisse, die personenbezogene Daten darstellen.
Architektur: Schwedischer Unternehmens-Informationsassistent
Eine reale Implementierung dieser Architektur ist in einem Assistenten fuer oeffentliche Informationen zu schwedischen Unternehmen zu sehen. Das System aggregiert Unternehmensinformationen aus mehreren autoritativen Quellen (Bolagsverket, Steuerverwaltung, Branchenregister) und bietet eine natuerlichsprachliche Schnittstelle fuer Anfragen.
Dateneigenschaften:
- Alle Quelldaten sind oeffentlich (Handelsregistereintraege, Finanzberichte, oeffentliche Aufzeichnungen)
- Benutzeranfragen offenbaren Geschaeftsinteressen, Wettbewerbsrecherche und Ermittlungsabsichten
- Das System bedient sowohl schwedische als auch EU-Nutzer
Technische Implementierung:
- Dokumentenindexierung: Oeffentliche Unternehmensdaten in selbst gehosteter Qdrant-Instanz indexiert
- Embeddings: Dokumente und Anfragen ueber EU-gehosteten Embedding-Service eingebettet
- Abruf: Vektoraehnlichkeitssuche identifiziert relevante Unternehmensinformationen
- Inferenz: Juicefactory.ai private EU-Inferenz generiert natuerlichsprachliche Antworten
- Antwort: Antwort mit Quellenverweisen auf autoritative Quellen zurueckgegeben
Compliance-Positionierung:
- Benutzeranfragen ohne Speicherung verarbeitet (transiente Verarbeitung gemaess Artikel 6 Abs. 1 lit. f DSGVO)
- Gesamte Verarbeitungsinfrastruktur in der EU angesiedelt
- Keine Datentransfers in Drittstaaten
- Dienst agiert als Auftragsverarbeiter mit dokumentierten Vereinbarungen
Diese Architektur zeigt, dass DSGVO-Konformitaet keinen Verzicht auf Funktionalitaet erfordert. Das System bietet moderne KI-Faehigkeiten bei gleichzeitiger Einhaltung strikter Datenverarbeitungsgrenzen.
 Beispiel eines Live-Assistenten fuer oeffentliche Informationen unter Verwendung von Retrieval-Augmented Generation und privater EU-basierter Inferenz.
Beispiel eines Live-Assistenten fuer oeffentliche Informationen unter Verwendung von Retrieval-Augmented Generation und privater EU-basierter Inferenz.
Zusammenfassung und naechste Schritte
DSGVO-konforme KI-Anwendungen erfordern architektonische Entscheidungen auf jeder Ebene: Vektordatenbanken muessen mit Kontrolle ueber den Datenstandort bereitgestellt werden, Embedding-Modelle muessen Anfragen ohne Speicherung verarbeiten, und Inferenz-Laufzeitumgebungen muessen als konforme Auftragsverarbeiter unter EU-Jurisdiktion operieren.
Die in diesem Leitfaden vorgestellte RAG-Architektur bietet einen praktischen Implementierungspfad:
- Vektordatenbank: Selbst gehostetes Qdrant oder pgvector in EU-Infrastruktur
- Embeddings: Selbst gehostete Modelle oder EU-basierte API-Dienste mit Auftragsverarbeitungsvertraegen
- Inferenz: Private EU-Laufzeitumgebung mit vertraglichen Garantien zur Datenverarbeitung
- Anwendungsschicht: Kundengesteuerte Protokollierung und Datenspeicherungsrichtlinien
Diese Architektur verwandelt Compliance von einer laufenden rechtlichen Aufgabe in eine strukturelle Garantie. Durch die Wahl von Infrastruktur, die DSGVO-Anforderungen systembedingt nicht verletzen kann, koennen Entwicklungsteams KI-Anwendungen ohne permanenten Compliance-Aufwand aufbauen.
Implementierungsressourcen
- Erste Schritte: API-Key erstellen fuer private EU-Inferenz
- Migration: Von OpenAI migrieren mit Schritt-fuer-Schritt-Anleitung
- Vergleich: EU-LLM-API-Vergleich zur Anbieterbewertung
- Preise: Deployment-Optionen fuer den Produktivbetrieb
Haeufig gestellte Fragen
Gilt die DSGVO, wenn ich nur oeffentliche Daten verarbeite?
Die DSGVO greift auf Basis der Verarbeitung personenbezogener Daten, nicht der Quelldaten. Selbst wenn die zugrundeliegenden Informationen oeffentlich sind, stellen Benutzeranfragen, Suchmuster und Interaktionsprotokolle personenbezogene Daten gemaess Artikel 4 Abs. 1 DSGVO dar. Wenn Ihr System Anfragen von EU-Buergern verarbeitet, gilt die DSGVO unabhaengig davon, ob die Antworten aus oeffentlichen Quellen stammen.
Ist EU-Hosting rechtlich fuer die DSGVO-Konformitaet vorgeschrieben?
EU-Hosting ist nicht zwingend vorgeschrieben -- die DSGVO erlaubt Datentransfers in Drittstaaten ueber Mechanismen nach Kapitel V (Angemessenheitsbeschluesse, Standardvertragsklauseln, verbindliche interne Datenschutzvorschriften). Diese Mechanismen erzeugen jedoch Compliance-Aufwand, rechtliche Unsicherheit und betriebliche Komplexitaet. EU-Hosting eliminiert Transferanforderungen vollstaendig und bietet einen einfacheren und robusteren Compliance-Pfad.
Wie reduzieren RAG-Systeme das Compliance-Risiko im Vergleich zu feinabgestimmten Modellen?
RAG-Systeme trennen Datenspeicherung (Vektordatenbank) von Modellinferenz (LLM-Laufzeitumgebung). Benutzerdaten beeinflussen die Antwortgenerierung durch den Abrufkontext, aendern aber keine Modellgewichte. Diese architektonische Trennung ermoeglicht die Kontrolle der Datenspeicherung, die Pruefung von Datenfluessen und die Umsetzung konformer Verarbeitung. Feinabgestimmte Modelle hingegen integrieren Trainingsdaten in die Modellgewichte, was die Loeschung einzelner Datenpunkte oder die Pruefung des Dateneinflusses erschwert.
Was ist der Unterschied zwischen Auftragsverarbeiter und Verantwortlichem bei KI-Diensten?
Gemaess Artikel 4 DSGVO legt der Verantwortliche Zweck und Mittel der Verarbeitung fest, waehrend der Auftragsverarbeiter Daten im Auftrag des Verantwortlichen verarbeitet. Bei KI-Diensten sind Sie (der Anwendungsentwickler) in der Regel der Verantwortliche, und der KI-Dienstanbieter ist der Auftragsverarbeiter. Diese Unterscheidung ist wichtig, weil Auftragsverarbeiter nach Ihren Weisungen handeln und Auftragsverarbeitungsvertraege (Artikel 28) unterzeichnen muessen, die ihre Datennutzung einschraenken. Private Inferenz-Dienste fungieren als Auftragsverarbeiter; oeffentliche KI-APIs agieren oft als Verantwortliche oder beanspruchen eine gemeinsame Verantwortlichkeit.
Kann ich diese Architektur fuer interne, mitarbeiterbezogene Anwendungen nutzen?
Ja. Die DSGVO gilt fuer Mitarbeiterdaten mit derselben Strenge wie fuer Kundendaten. Interne KI-Anwendungen, die Mitarbeiteranfragen, Personalinformationen oder Geschaeftsdokumente verarbeiten, erfordern dieselben Compliance-Massnahmen. Die in diesem Leitfaden beschriebene Architektur gilt gleichermassen fuer interne und externe Anwendungen.
Speichert JuiceFactory Benutzer-Prompts?
Nein. JuiceFactory AI agiert als zustandsloser Inferenz-Dienst und speichert weder Benutzer-Prompts noch Antworten oder anfragebezogene Daten. Dies ist eine vertragliche Garantie im Rahmen der Auftragsverarbeitungsvertraege gemaess Artikel 28 DSGVO, nicht lediglich eine Richtlinienerklarung. Prompts werden im GPU-Speicher verarbeitet und nach der Antwortgenerierung verworfen. Betriebliche Protokolle enthalten Anfrage-Metadaten (Zeitstempel, Anfrage-ID, Modellversion, Latenz, Token-Anzahl), aber weder Prompt-Inhalte noch Antworten.
Welche Modelle sind ueber EU-gehostete Inferenz verfuegbar?
JuiceFactory AI bietet Zugang zu Frontier-Modellen wie GPT-4-Klasse, Claude und Llama-3-70B ueber EU-Infrastruktur. Die Modellverfuegbarkeit aendert sich regelmaessig, wenn neue Versionen verfuegbar werden. Den aktuellen Modellkatalog finden Sie in der API-Dokumentation.
Wie verhaelt sich die Preisgestaltung im Vergleich zu OpenAI?
Private EU-Inferenz kostet in der Regel das 1,5- bis 2-fache der oeffentlichen API-Preise, bedingt durch dedizierte Infrastruktur und Compliance-Aufwand. Fuer Organisationen mit weniger als 1.000 EUR monatlichen KI-Ausgaben koennen oeffentliche APIs kosteneffizienter sein. Fuer Enterprise-Deployments (ab 10.000 EUR/Monat) rechtfertigen die Compliance-Vorteile den Aufpreis. Detaillierte Preise finden Sie im Portal.
Unterstuetzt LangChain EU-gehostete Inferenz?
Ja. LangChain und andere OpenAI-kompatible Frameworks funktionieren nahtlos mit EU-gehosteten Endpunkten. Beispiele finden Sie im Abschnitt Framework-Integration weiter oben. Jedes Framework, das OpenAIs API unterstuetzt, kann EU-gehostete Inferenz ohne Modifikation nutzen.
Wie kann ich Inferenz-Anfragen ueberwachen und beobachten?
JuiceFactory AI liefert Standard-API-Response-Header mit Verarbeitungszeit, Region und Token-Verbrauch. Fuer anwendungsseitiges Monitoring muessen Sie die Protokollierung in Ihrer Anwendungsschicht implementieren. Betriebliche Metriken (Latenz, Fehlerraten, Token-Verbrauch) koennen ueber Ihr API-Dashboard verfolgt werden. Da Anfragen auf Infrastrukturebene nicht gespeichert werden, muessen anfragebezogene Analysen bei Bedarf in Ihrer Anwendung implementiert werden.
Ist zustandslose Inferenz wirklich DSGVO-konform?
Zustandslose Inferenz -- bei der Anfragen im Arbeitsspeicher ohne persistente Speicherung verarbeitet werden -- erfuellt die DSGVO-Anforderungen zur Datenminimierung (Artikel 5 Abs. 1 lit. c), wenn sie korrekt implementiert wird. Die Konformitaet beruht auf drei technischen Garantien: keine Anfragenprotokollierung, ordnungsgemaesses Speicher-Lifecycle-Management und keine Speicherung von Ableitungen. JuiceFactory AI implementiert zustandslose Verarbeitung mit diesen Garantien, sodass Organisationen Inferenz gemaess Artikel 6 Abs. 1 lit. f DSGVO (berechtigtes Interesse) fuer transiente Verarbeitung nutzen koennen. Organisationen koennen die zustandslose Verarbeitung durch Infrastruktur-Audits, Netzwerkanalyse und die Pruefrechte nach Artikel 28 verifizieren.
Verwandte Leitfaeden
- RAG with Python: GDPR Document Search - Praktische Implementierung von Vektorsuche mit EU-Inferenz
- RAG with Qwen: EU-Hosted Embeddings - Verwendung von Qwen-Modellen fuer DSGVO-konforme RAG
- Stateless LLM API for GDPR - Tiefgehende Betrachtung der zustandslosen Verarbeitungsarchitektur
- EU LLM API Comparison - Vergleich EU-gehosteter KI-Anbieter
- Migrate from OpenAI to EU API - Schritt-fuer-Schritt-Migrationsleitfaden