Jak vytvářet aplikace AI v souladu s GDPR pomocí soukromé EU inference
Úvod: Adopce AI se setkává s realitou compliance
Umělá inteligence se přesunula z experimentů do produkčních systémů. Vyhledávací asistenti, automatizační workflow a nástroje na podporu rozhodování jsou nyní součástí každodenních operací.
Pro týmy operující v Evropě nebo obsluhující evropské uživatele se jedno omezení stává nevyhnutelným: kde probíhá AI inference má stejný význam jako to, co model dokáže.
Dokonce i když jsou podkladová data veřejná, uživatelské dotazy, záměry a vzorce interakce vyžadují pečlivé zacházení. Tento průvodce vysvětluje, jak lze soukromou EU-založenou AI inferenci použít k vytváření vyhovujících, praktických AI aplikací s využitím retrieval-augmented generation (RAG).
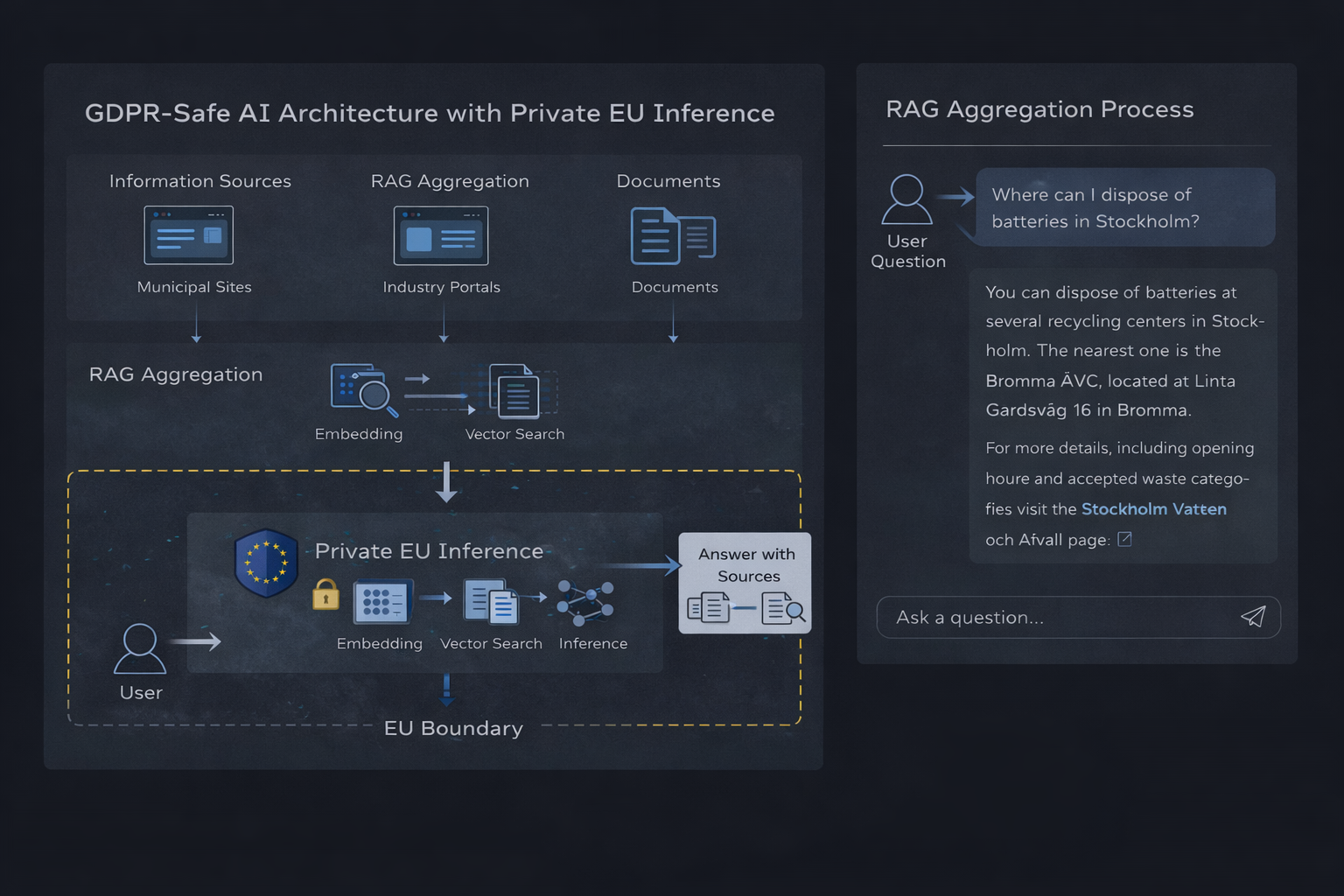 Architektura soukromé EU-založené AI inference s RAG agregací
Architektura soukromé EU-založené AI inference s RAG agregací
Kdy je soukromá AI inference správnou volbou
Soukromá AI inference není vyžadována pro každý případ použití. Stává se relevantní, když aplikace musí operovat v rámci jasných datových hranic, předvídatelné správy a explicitních omezení compliance.
Typické scénáře zahrnují služby veřejných informací, interní znalostní systémy, automatizační pipeline a regulovaná prostředí, kde lokalita dat a kontrola zpracování nejsou předmětem vyjednávání.
Juicefactory.ai poskytuje soukromé runtime prostředí inference umístěné v EU, speciálně navržené pro tyto scénáře. Systém neukládá osobní údaje a nepoužívá zákaznická data k tréninku modelu. Jeho role je omezena pouze na inferenci.
Technická architektura: retrieval-augmented generation
Retrieval-augmented generation kombinuje tradiční vyhledávání s uvažováním jazykového modelu. Místo toho, aby model odpovídal volně, systém načte ověřený kontext a omezí odpověď na tyto informace.
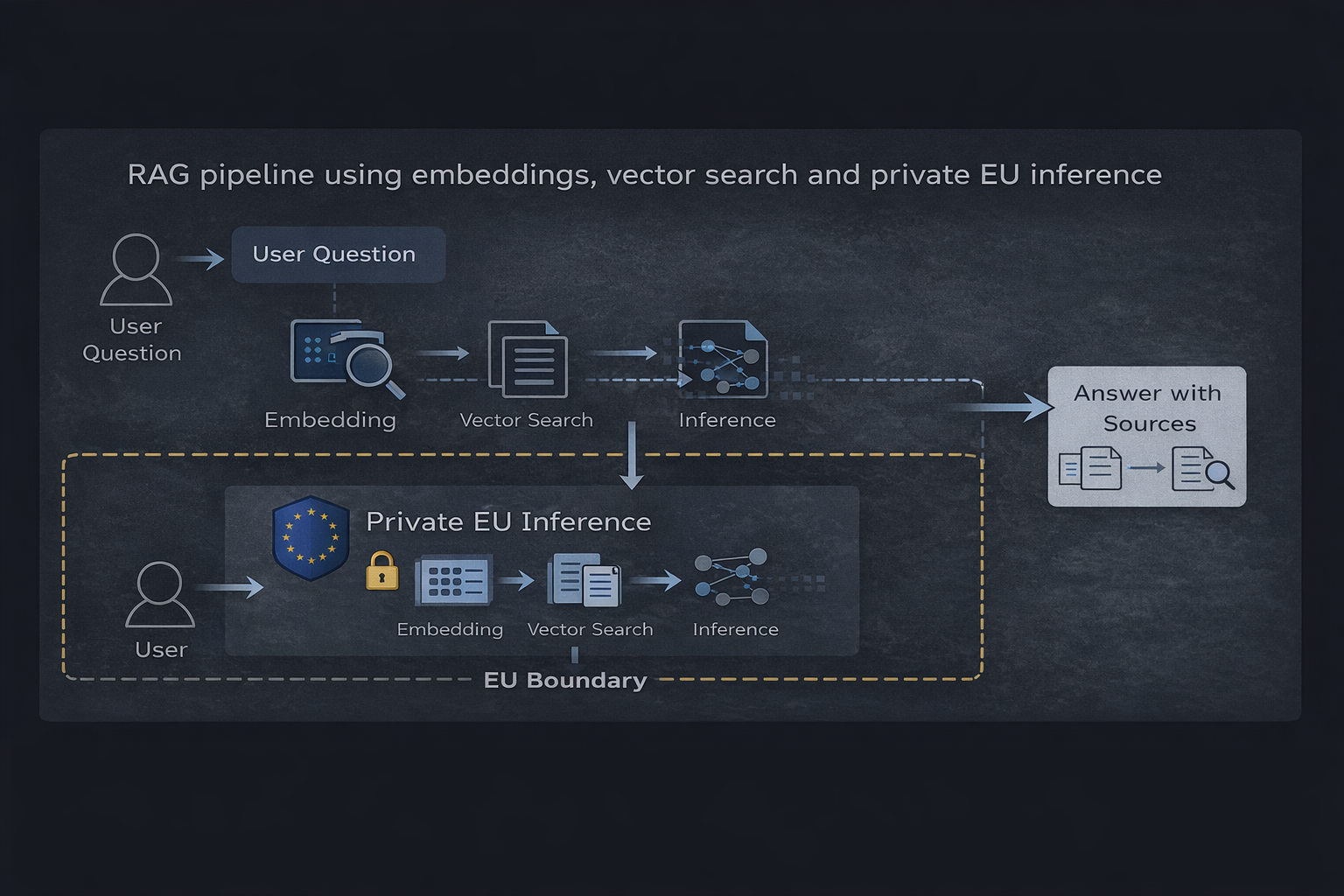 RAG pipeline používající embeddings, vektorové vyhledávání a soukromou EU inferenci
RAG pipeline používající embeddings, vektorové vyhledávání a soukromou EU inferenci
Hlavní komponenty
- Vektorová databáze (jako Qdrant) ukládající indexovaný obsah
- Embeddings použité k reprezentaci dokumentů a otázek
- Vrstva načítání vybírající relevantní kontext
- Soukromé runtime prostředí inference generující podložené odpovědi
Tok je jednoduchý: uživatelská otázka je vložena, relevantní informace jsou načteny a model vytvoří odpověď pouze na základě tohoto kontextu.
Praktický příklad: zjednodušení přístupu k veřejným informacím
Veřejné informace jsou často distribuovány napříč mnoha autoritativními zdroji. Městské webové stránky, oborové portály a oficiální dokumenty mohou všechny obsahovat správné informace, ale přesto být pro uživatele obtížné k navigaci.
Praktický příklad tohoto přístupu lze vidět v reálném experimentu, který zkoumá, jak AI může zjednodušit přístup k národně fragmentovaným informacím bez nahrazení místní autority.
Systém načte relevantní obsah, vygeneruje vysvětlení a nasměruje uživatele ke správnému autoritativnímu zdroji — snižuje tření při zachování důvěry.
 Příklad živého asistenta veřejných informací využívajícího retrieval-augmented generation a soukromou EU-založenou inferenci.
Příklad živého asistenta veřejných informací využívajícího retrieval-augmented generation a soukromou EU-založenou inferenci.
Proč záleží na umístění inference pro GDPR
Dokonce i když je podkladový obsah veřejný, proces inference interpretuje záměr uživatele a kontextové dotazy. Toto zpracování může spadat pod úvahy GDPR, což činí umístění inference a praktiky zpracování dat kritickými.
Provozování inference v rámci EU poskytuje jasnější regulační hranice, předvídatelnou správu a větší transparentnost jak pro provozovatele, tak pro uživatele.
Shrnutí
Soukromá EU-založená AI inference umožňuje kombinovat moderní AI schopnosti s odpovědným zacházením s daty. Spárováním retrieval-augmented generation s řízeným runtime prostředím inference mohou týmy vytvářet užitečné, vyhovující systémy bez obětování použitelnosti nebo kontroly.
Prozkoumejte, jak nahrazení externích poskytovatelů inference infrastrukturou založenou v EU funguje v praxi, nebo se dozvíte, jak se automatizační workflow integrují se soukromou AI pro end-to-end compliance.