GDPR-säkra AI-applikationer: Privat EU-inferens med RAG (arkitekturguide)
Att bygga AI-applikationer som behandlar användarfrågor kräver noggranna överväganden kring GDPR-efterlevnad. Även när underliggande data är offentlig utgör användarens avsikt, sökmönster och interaktionsdata personuppgifter som omfattas av dataskyddsförordningen.
Den här guiden beskriver en teknisk arkitektur för att bygga GDPR-säkra AI-applikationer med privat EU-baserad inferens kombinerad med retrieval-augmented generation (RAG). Tillvägagångssättet riktar sig till utvecklingsteam och dataskyddsansvariga som behöver implementera AI-funktionalitet och samtidigt upprätthålla regulatorisk efterlevnad.
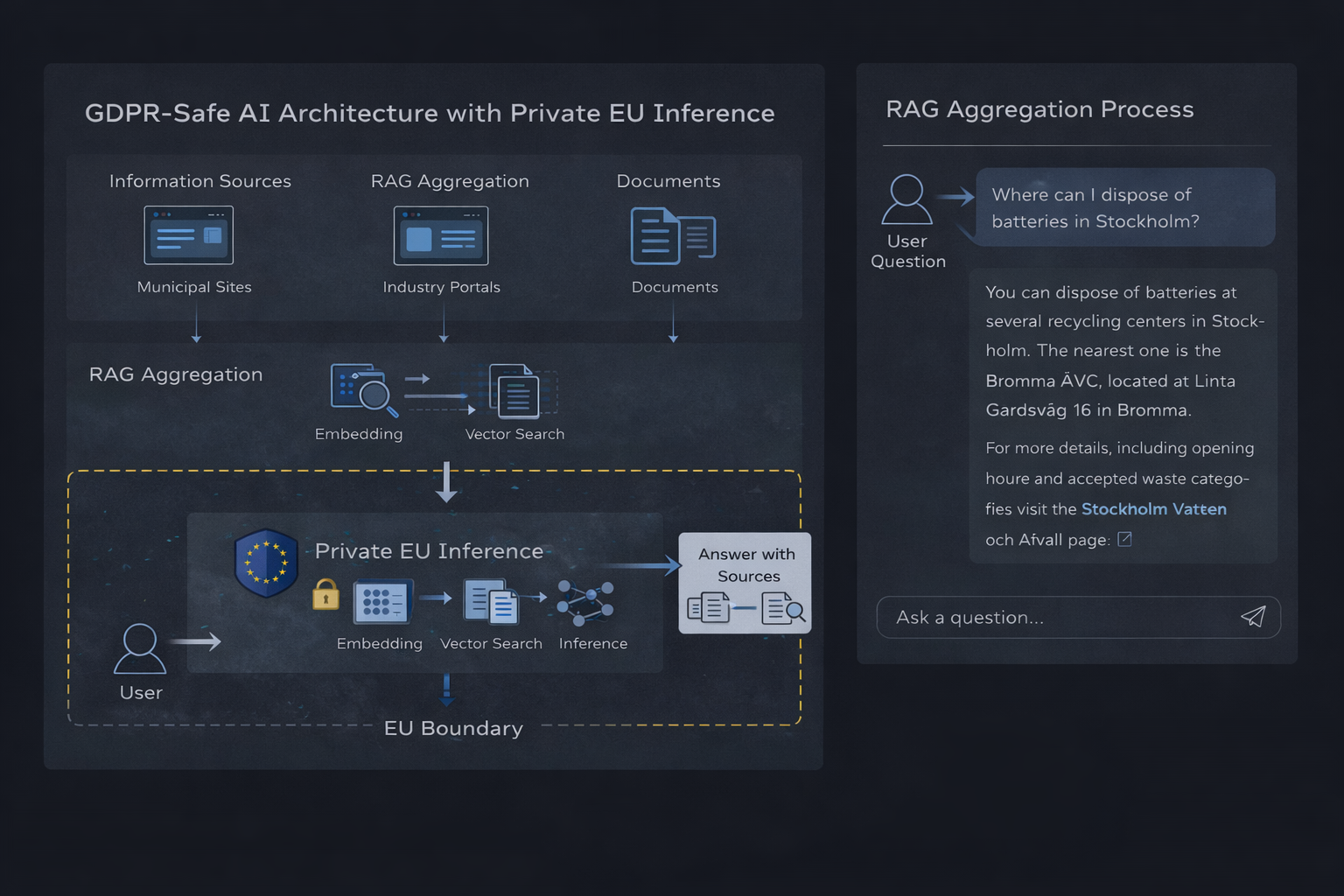 Privat EU-baserad AI-inferens-arkitektur med RAG-aggregering
Privat EU-baserad AI-inferens-arkitektur med RAG-aggregering
Snabbstart
Om du redan använder OpenAI och bara vill byta till GDPR-säker EU-hosting gör du så här:
from openai import OpenAI
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explain GDPR Article 28 requirements."}]
)
print(response.choices[0].message.content)
Det var allt. Inga kodändringar utöver base URL och API-nyckel. Dina frågor behandlas nu i EU-infrastruktur med avtalsmässiga garantier för datahantering. Se migreringsguiden för detaljer.
GDPR-krav för AI-inferens
GDPR-efterlevnad för AI-system bygger på tre centrala principer: dataminimering, ändamålsbegränsning och territoriell jurisdiktion.
Dataminimering innebär att du bara får behandla de uppgifter som är nödvändiga för det angivna ändamålet. Vid AI-inferens betyder det att du ska undvika att lagra användarfrågor, konversationshistorik eller härledda insikter utöver vad som krävs operationellt.
Ändamålsbegränsning begränsar användningen av behandlade uppgifter till det angivna syftet. AI-leverantörer som använder kunders frågor för att förbättra modeller eller träna framtida versioner bryter mot denna princip. Regelefterlevande system måste implementera strikt isolering mellan inferensverksamhet och alla former av datalagring eller modellträning.
Territoriell jurisdiktion avgör vilket regelverk som gäller. GDPR artikel 3 fastställer att behandling av EU-medborgares uppgifter faller under EU:s jurisdiktion oavsett var organisationen är etablerad. Det gör den fysiska placeringen av inferensinfrastruktur till ett efterlevnadskrav, inte bara en arkitekturell preferens.
Privat EU-baserad inferens adresserar dessa krav genom att:
- Behandla frågor i realtid utan beständig lagring
- Isolera kunddata från modellträningspipelines
- Driva inferensinfrastruktur inom EU:s territoriella gränser
- Tillhandahålla avtalsmässiga garantier för datahantering och personuppgiftsbiträdesförhållanden (artikel 28)
Juicefactory.ai agerar som personuppgiftsbiträde enligt GDPR artikel 28, med dokumenterade biträdesavtal och tekniska garantier för datahantering. Inga frågor sparas, ingen data används för träning, och all behandling sker inom EU-infrastruktur. Se privat inferens-runtime för detaljer.
Varför EU-hosting är avgörande för efterlevnad
Den fysiska placeringen av AI-inferensinfrastruktur påverkar direkt regulatorisk efterlevnad, datasuveränitet och rättslig verkställbarhet.
Regulatorisk tydlighet: EU-hostad infrastruktur verkar under ett enda regelverk. När inferens körs i EU har dataskyddsmyndigheter tydlig jurisdiktion, personuppgiftsbiträden verkar under kända rättsliga krav, och registrerade har verkställbara rättigheter genom etablerade förfaranden.
Undvikande av dataöverföringar: GDPR kapitel V ställer strikta krav på överföring av personuppgifter till tredjeland. EU-till-USA-överföringar kräver beslut om adekvat skyddsnivå, standardavtalsklausuler eller alternativa mekanismer som skapar efterlevnadsbörda och juridisk osäkerhet. Att hålla inferens inom EU:s gränser eliminerar dessa överföringskrav helt.
Biträdesansvar: Enligt GDPR artikel 28 måste personuppgiftsbiträden visa efterlevnad genom tekniska och organisatoriska åtgärder. EU-baserade biträden verkar under direkt tillsyn av dataskyddsmyndigheter, omfattas av samma krav på incidentrapportering, och kan granskas enligt etablerade förfaranden.
Suveränitet och kontroll: EU-hosting säkerställer att rättsprocesser, myndighetsförfrågningar och datatillgång följer EU-förfaranden. Hosting utanför EU kan innebära att data underkastas utländska rättsliga ramverk, extraterritoriell övervakning eller motstridiga rättsliga skyldigheter.
Den praktiska konsekvensen för AI-system är tydlig: EU-hosting förvandlar efterlevnad från en pågående juridisk insats till en arkitekturell garanti.
RAG-systemarkitektur för GDPR-efterlevnad
Retrieval-augmented generation (RAG) kombinerar informationssökning med språkmodellsinferens för att producera grundade och verifierbara svar. Arkitekturen består av fyra distinkta komponenter, var och en med specifika efterlevnadsöverväganden.
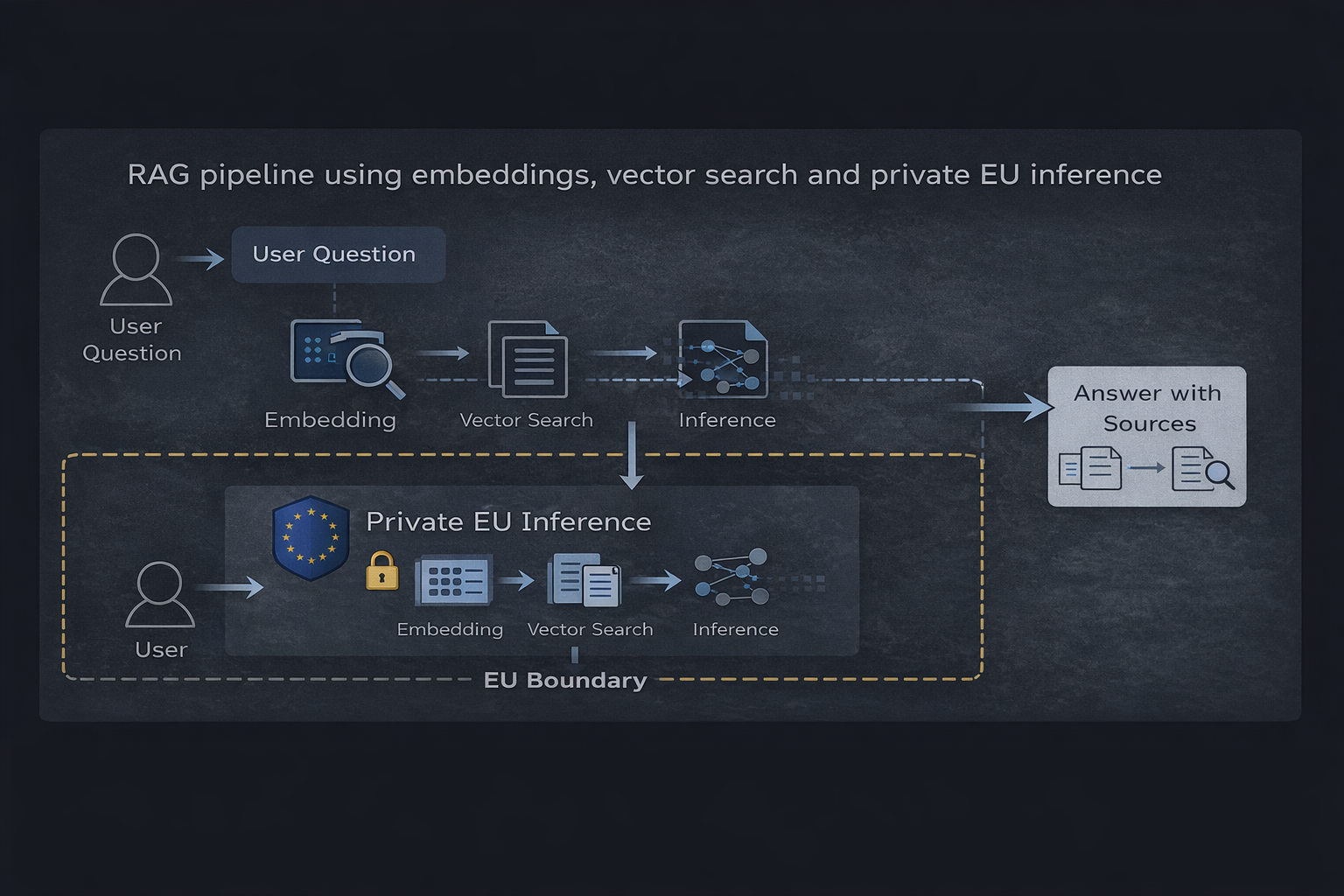 RAG-pipeline som använder embeddings, vektorsökning och privat EU-inferens
RAG-pipeline som använder embeddings, vektorsökning och privat EU-inferens
Arkitekturöversikt
1. Vektordatabas lagrar inbäddade representationer av källdokument. Databasen i sig innehåller härledd data (embeddings) snarare än råa användarfrågor, vilket gör den lämplig för beständig lagring med lämpliga åtkomstkontroller.
2. Embedding-tjänst konverterar användarfrågor och dokument till vektorrepresentationer. Detta behandlingssteg får inte spara frågedata eller använda den för träningssyften.
3. Hämtningslager utför vektorsökning baserad på likhet för att identifiera relevant kontext. Denna komponent behandlar användarfrågor transient utan beständig lagring.
4. Inferens-runtime genererar svar baserat på hämtad kontext. Detta är den kritiska efterlevnadsgränsen — körmiljön måste behandla frågor utan lagring, loggning eller insamling av träningsdata.
Dataflöde och efterlevnadsgränser
- Användaren skickar en fråga (personuppgift enligt GDPR)
- Frågan bäddas in utan lagring (transient behandling)
- Vektorsökning hämtar relevant kontext (inga personuppgifter involverade)
- Kontext och fråga skickas till EU-inferens-runtime
- Svar genereras och returneras (ingen lagring av fråga eller svar)
- Valfritt: Svaret loggas av applikationslagret (under kundens kontroll)
Den centrala efterlevnadsfunktionen i denna arkitektur är isolering: personuppgifter (användarfrågor) flödar genom systemet utan beständig lagring på infrastrukturnivå. All datalagring sker inom applikationslagret under kundens kontroll, inte hos tjänsteleverantören.
Ett praktiskt implementationsexempel hittar du i vår RAG med Python-guide.
Val av vektordatabas (Qdrant, pgvector med mera)
Valet av vektordatabas påverkar prestanda, operationell komplexitet och efterlevnadsposition. De primära alternativen är specialiserade vektordatabaser (Qdrant, Weaviate, Milvus), PostgreSQL-tillägg (pgvector) och hanterade tjänster (Pinecone, AWS OpenSearch).
Qdrant
Qdrant är en vektordatabas med öppen källkod, specifikt designad för likhetssökning. Den stöder HNSW-indexering, filtrerad sökning och distribuerade driftsättningar.
Efterlevnadsfördelar:
- Kan hostas internt i EU-infrastruktur
- Inga telemetri- eller uppringningskrav
- Tydliga datagränser (lagrar bara det du indexerar)
- Lämplig för air-gapped-driftsättningar
Operationella egenskaper:
- Kräver dedikerad infrastruktur
- Inbyggd klustring för horisontell skalning
- gRPC- och HTTP-API:er för integration
pgvector
pgvector är ett PostgreSQL-tillägg som lägger till vektorsökning baserad på likhet i befintliga PostgreSQL-databaser.
Efterlevnadsfördelar:
- Utnyttjar befintlig PostgreSQL-infrastruktur och efterlevnadskontroller
- Inga ytterligare externa beroenden
- Data stannar inom etablerade databasgränser
- Välkänd operationsmodell för team som redan kör PostgreSQL
Operationella egenskaper:
- Begränsad till approximativ nearest-neighbor-sökning (HNSW, IVFFlat)
- Prestanda lämplig för små till medelstora datamängder (<10M vektorer)
- Enkel integration med befintliga applikationsdatabaser
Urvalskriterier för GDPR-efterlevnad
För GDPR-efterlevande arkitekturer är de avgörande beslutsfaktorerna:
- Hostingkontroll: Kan databasen driftsättas i EU-infrastruktur?
- Dataisolering: Samlar databasen in telemetri, användningsdata eller metadata utöver det du explicit lagrar?
- Operationell kompetens: Har ditt team kapacitet att driva infrastrukturen?
Hanterade tjänster (Pinecone, Weaviate Cloud) förenklar driften men kräver noggrann utvärdering av deras biträdesavtal och hostingplatser. Självhostade lösningar (Qdrant, pgvector) ger maximal kontroll men kräver operationell kapacitet.
För de flesta efterlevnadsfokuserade användningsfall ger självhostad Qdrant eller pgvector i EU-infrastruktur den tydligaste efterlevnadsvägen. Se vår Qwen RAG-guide för implementationsexempel.
Embedding-modeller och integritetsöverväganden
Embedding-modeller konverterar text till vektorrepresentationer för likhetssökning. Valet av embedding-modell och hur den driftas påverkar direkt integritet och efterlevnad.
Alternativ för embedding-modeller
Moln-API:er (OpenAI embeddings, Cohere, Voyage) behandlar text via externa tjänster. Dessa tjänster tar emot fullständig text av användarfrågor och dokument. De flesta molnleverantörer av embeddings förbehåller sig uttryckligen rätten att använda indata för modellförbättring, vilket gör dem olämpliga för integritetskänsliga tillämpningar.
Självhostade modeller (sentence-transformers, nomic-embed, bge-*-modeller) körs på din egen infrastruktur och behandlar data lokalt. Dessa modeller ger full kontroll över dataflödet och eliminerar externa dataöverföringar.
Privata API-tjänster som Juicefactory.ai tillhandahåller embedding-API:er med avtalsmässiga garantier för datahantering. Dessa tjänster behandlar embeddings utan lagring eller insamling av träningsdata, och fungerar som GDPR-efterlevande personuppgiftsbiträden.
Integritets- och efterlevnadsöverväganden
Den avgörande efterlevnadsfrågan för embeddings är: Ser och sparar embedding-tjänsten användarfrågor?
Vid dokumentindexering är integritetsriskerna minimala — dokumenten som bäddas in är vanligtvis inte personuppgifter, och indexeringen sker som en batchprocess under din kontroll.
Vid fråge-embeddings är integriteten kritisk. Varje användarfråga behandlas av embedding-tjänsten. Om den tjänsten sparar frågor, loggar dem eller använder dem för träning skapas en efterlevnadsskyldighet och potentiell dataintrångsrisk.
Efterlevande embedding-arkitektur:
- Använd självhostade embedding-modeller för maximal kontroll
- Om du använder ett externt embedding-API, verifiera avtalsmässiga garantier för datahantering
- Säkerställ att embedding-tjänster verkar som personuppgiftsbiträden enligt GDPR artikel 28
- Föredra EU-hostade tjänster för att undvika gränsöverskridande dataöverföringar
Juicefactory.ai tillhandahåller embedding-API:er parallellt med inferenstjänster, med samma efterlevnadsgarantier: ingen datalagring, ingen insamling av träningsdata, EU-hosting och biträdesavtal. Se API-dokumentation för implementationsdetaljer.
Konfiguration av privat inferens-runtime
Inferens-körmiljön är den komponent som behandlar användarfrågor och genererar svar. Detta är den mest kritiska efterlevnadsgränsen i arkitekturen.
Efterlevnadskrav för inferens
En GDPR-efterlevande inferens-runtime måste:
- Behandla frågor utan lagring: Frågor behandlas i minnet och kasseras efter att svaret genererats
- Isolera kunddata från träning: Ingen frågedata, inga svar eller härledd information används för att träna eller förbättra modeller
- Verka inom EU:s jurisdiktion: Infrastrukturen körs i EU-datacenter under EU:s rättsliga ramverk
- Fungera som personuppgiftsbiträde: Tjänsten verkar enligt GDPR artikel 28 med dokumenterade biträdesavtal
- Tillhandahålla revisionsmöjligheter: Kunder kan verifiera efterlevnad genom tekniska och avtalsmässiga åtgärder
Privat inferens kontra publika API:er
Publika AI-API:er (OpenAI, Anthropic, Google) är utformade för modellutveckling och förbättring. Deras användarvillkor ger vanligtvis breda rättigheter att använda kunddata för träning och kvalitetsförbättring. Även när "opt-out"-mekanismer finns kräver de aktiv konfiguration och gäller inte nödvändigtvis all behandlingsverksamhet.
Privata inferenstjänster är arkitekturellt utformade för efterlevnad. Datahanteringen är avtalsmässigt begränsad, infrastrukturen är dedikerad eller isolerad, och tjänsten verkar som personuppgiftsbiträde snarare än personuppgiftsansvarig.
Implementation med Juicefactory.ai
Juicefactory.ai tillhandahåller privat EU-baserad inferens genom ett OpenAI-kompatibelt API. Tjänsten stöder:
- EU-hosting: All inferens körs i EU-datacenter
- Ingen datalagring: Frågor och svar sparas inte
- Ingen insamling av träningsdata: Kunddata används aldrig för modellförbättring
- Biträdesavtal: GDPR artikel 28-efterlevande personuppgiftsbiträdesavtal
- OpenAI API-kompatibilitet: Drop-in-ersättning för befintliga OpenAI-integrationer
Implementationsexempel (moderna OpenAI SDK v1.x+):
from openai import OpenAI
# Configure to use private EU inference
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
# Standard OpenAI API calls now route through private EU infrastructure
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain GDPR Article 28 requirements."}
]
)
print(response.choices[0].message.content)
Inga kodändringar krävs utöver API-endpointkonfiguration. Befintliga applikationer som använder OpenAI-SDK:er kan byta till privat inferens genom att uppdatera base URL och API-nyckel.
Se portal för driftsättningsalternativ och jämförelseguide för funktionsanalys.
Ramverksintegration
Moderna AI-ramverk fungerar sömlöst med OpenAI-kompatibla endpoints. Så här integrerar du med populära verktyg:
LangChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.invoke("Explain GDPR data minimization principle")
print(response.content)
LlamaIndex
from llama_index.llms.openai import OpenAI
llm = OpenAI(
api_base="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.complete("Explain GDPR data minimization principle")
print(response.text)
curl (direkt API)
curl https://api.juicefactory.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jf_your_key_here" \
-d '{
"model": "gpt-4",
"messages": [{"role": "user", "content": "Explain GDPR Article 28"}]
}'
Alla ramverk som stöder OpenAI:s API fungerar utan modifiering — du pekar dem bara mot den EU-baserade endpointen. Fler integrationsexempel finns i vår guide om tillståndslösa LLM-API:er.
Varför single-GPU-inferens med högminne är viktigt för efterlevnad
Infrastrukturarkitekturen påverkar direkt GDPR-efterlevnadsgarantierna. Single-GPU-inferens med högminne ger isoleringsegenskaper som distribuerade system inte kan matcha.
Efterlevnadsutmaningen med modellsharding
Stora språkmodeller överskrider ofta minneskapaciteten för en enskild GPU, vilket tvingar driftsättning över flera GPU:er eller noder. Denna distribution skapar sårbarhet ur dataskyddsperspektiv:
Risk för läckage mellan noder: När en modell är shardad över flera GPU:er eller servrar flödar frågedata genom flera minnesrymder. Varje gräns utgör en potentiell läckagepunkt. Felsökningsverktyg, minnesdumpar eller systemfel kan exponera frågefragment över hela infrastrukturen.
Ökad attackyta: Varje ytterligare nod mångdubblar attackytan. Sidokanalattacker mot minnet (Spectre, Meltdown-varianter) blir mer effektiva när frågedata är distribuerad över delad infrastruktur.
Single-GPU-fördelar för GDPR-efterlevnad
GPU:er med högminne (96 GB, 128 GB eller mer) kan hosta stora modeller (70B parametrar, GPT-4-klass) inom en enda minnesrymd. Denna arkitekturella förenkling ger efterlevnadsfördelar:
Förutsägbar isolering: All inferens sker inom en enda GPU:s minne. Frågedata korsar aldrig minnesgränser, nätverksgränssnitt eller IPC-kanaler. Datavägen är deterministisk och reviderbar.
Atomisk behandling: Varje fråga går in i GPU-minnet, genomgår inferens, producerar ett svar och kasseras — helt inom kiselbegränsningar. Ingen mellanlagring, ingen koordinering mellan noder, inga residuala data i systemminnet.
Begränsad skaderadie: Säkerhetsincidenter begränsas till en enskild GPU. Minneskompromisser kan inte sprida sig över infrastrukturen, vilket begränsar exponeringsomfånget.
JuiceFactory infrastrukturmodell
JuiceFactory AI kör inferens på dedikerade högminnes-GPU:er (96 GB+) med single-model-instanser:
- Ingen modellsharding: Varje GPU hostar en komplett modell i sitt eget minne
- Ingen multi-tenancy på GPU-nivå: Kundfrågor delar inte GPU-minnesrymd
- Efemär behandling: GPU-minnet rensas mellan förfrågningar
- Single-region-behandling: Frågor traverserar aldrig andra regioner
| Arkitektur | Minneseffektivitet | Reviderbarhet | Isoleringsgarantier |
|---|---|---|---|
| Distribuerad (4x24 GB) | Hög | Komplex | Probabilistisk |
| Single GPU (96 GB) | Måttlig | Enkel | Deterministisk |
För GDPR-kritiska applikationer ger single-GPU-modellen den tydligaste efterlevnadsvägen.
Praktiskt exempel: assistent för offentlig information
Offentliga informationssystem utgör ett tydligt användningsfall för GDPR-säker AI: även när underliggande data är offentlig avslöjar användarfrågor avsikt, intressen och informationsbehov som utgör personuppgifter.
Arkitektur: svensk företagsinformationsassistent
En verklig implementation av denna arkitektur kan ses i en offentlig informationsassistent för svenska företag. Systemet aggregerar företagsinformation från flera auktoritativa källor (Bolagsverket, Skatteverket, branschregister) och tillhandahåller ett naturligt språkgränssnitt för frågor.
Datakaraktäristik:
- All källdata är offentlig (företagsregistreringar, finansiella rapporter, offentliga handlingar)
- Användarfrågor avslöjar affärsintressen, konkurrensanalys och utredningsavsikter
- Systemet betjänar både svenska och EU-användare
Teknisk implementation:
- Dokumentindexering: Offentlig företagsdata indexerad i självhostad Qdrant-instans
- Embeddings: Dokument och frågor inbäddade med EU-hostad embedding-tjänst
- Hämtning: Vektorsökning baserad på likhet identifierar relevant företagsinformation
- Inferens: Juicefactory.ai privat EU-inferens genererar svar på naturligt språk
- Svar: Svar returneras med hänvisningar till auktoritativa källor
Efterlevnadsposition:
- Användarfrågor behandlas utan lagring (transient behandling enligt GDPR artikel 6.1 f)
- All behandlingsinfrastruktur befinner sig i EU
- Inga dataöverföringar till tredjeland
- Tjänsten verkar som personuppgiftsbiträde med dokumenterade avtal
Denna arkitektur visar att GDPR-efterlevnad inte kräver att du offrar funktionalitet. Systemet levererar moderna AI-förmågor samtidigt som strikta datahanteringsgränser upprätthålls.
 Exempel på en live offentlig-informationsassistent som använder retrieval-augmented generation och privat EU-baserad inferens.
Exempel på en live offentlig-informationsassistent som använder retrieval-augmented generation och privat EU-baserad inferens.
Sammanfattning och nästa steg
GDPR-efterlevande AI-applikationer kräver arkitekturbeslut i varje lager: vektordatabaser måste driftsättas med kontroll över datalokaliseringen, embedding-modeller måste behandla frågor utan lagring, och inferens-körmiljöer måste fungera som regelefterlevande personuppgiftsbiträden inom EU:s jurisdiktion.
RAG-arkitekturen som presenteras i denna guide ger en praktisk implementationsväg:
- Vektordatabas: Självhostad Qdrant eller pgvector i EU-infrastruktur
- Embeddings: Självhostade modeller eller EU-baserade API-tjänster med biträdesavtal
- Inferens: Privat EU-runtime med avtalsmässiga garantier för datahantering
- Applikationslager: Kundkontrollerad loggning och datalagringsregler
Denna arkitektur flyttar efterlevnad från pågående juridisk insats till strukturell garanti. Genom att välja infrastruktur som inte kan bryta mot GDPR-kraven kan utvecklingsteam bygga AI-applikationer utan kontinuerlig efterlevnadsbörda.
Implementationsresurser
- Kom igång: Skapa API-nyckel för privat EU-inferens
- Migrering: Migrera från OpenAI med steg-för-steg-instruktioner
- Jämförelse: Jämförelse av EU LLM-API:er för leverantörsutvärdering
- Priser: Driftsättningsalternativ för produktionsanvändning
Vanliga frågor
Gäller GDPR om jag bara behandlar offentlig data?
GDPR gäller baserat på behandling av personuppgifter, inte källdatan. Även när underliggande information är offentlig utgör användarfrågor, sökmönster och interaktionsloggar personuppgifter enligt GDPR artikel 4.1. Om ditt system behandlar frågor från EU-medborgare gäller GDPR oavsett om svaren kommer från offentliga källor.
Krävs EU-hosting för GDPR-efterlevnad?
EU-hosting är inte strikt nödvändigt — GDPR tillåter dataöverföringar till tredjeland enligt kapitel V-mekanismer (beslut om adekvat skyddsnivå, standardavtalsklausuler, bindande företagsregler). Dessa mekanismer skapar dock efterlevnadsbörda, juridisk osäkerhet och operationell komplexitet. EU-hosting eliminerar överföringskraven helt och ger en enklare och mer robust efterlevnadsväg.
Hur minskar RAG-system efterlevnadsrisken jämfört med finjusterade modeller?
RAG-system separerar datalagring (vektordatabas) från modellinferens (LLM-runtime). Användardata påverkar svarsgenereringen genom hämtad kontext men ändrar inte modellens vikter. Denna arkitekturella separation gör det möjligt att kontrollera datalagring, granska dataflöden och implementera regelefterlevande behandling. Finjusterade modeller, däremot, inkorporerar träningsdata i modellvikter, vilket gör det svårt att radera specifika datapunkter eller granska datapåverkan.
Vad är skillnaden mellan personuppgiftsbiträde och personuppgiftsansvarig för AI-tjänster?
Enligt GDPR artikel 4 är en personuppgiftsansvarig den som bestämmer ändamålen och medlen för behandlingen, medan ett personuppgiftsbiträde behandlar data på den ansvariges vägnar. För AI-tjänster är du (applikationsutvecklaren) vanligtvis personuppgiftsansvarig, och AI-tjänsteleverantören är personuppgiftsbiträde. Denna distinktion är viktig eftersom biträden verkar enligt dina instruktioner och måste teckna biträdesavtal (artikel 28) som begränsar deras användning av data. Privata inferenstjänster fungerar som biträden; publika AI-API:er fungerar ofta som personuppgiftsansvariga eller hävdar gemensamt personuppgiftsansvar.
Kan jag använda denna arkitektur för interna medarbetarapplikationer?
Ja. GDPR gäller för medarbetardata med samma stringens som för kunddata. Interna AI-applikationer som behandlar medarbetarfrågor, HR-information eller affärsdokument kräver samma efterlevnadsåtgärder. Arkitekturen som beskrivs i denna guide är lika tillämpbar på interna som externa applikationer.
Lagrar JuiceFactory användarpromptar?
Nej. JuiceFactory AI verkar som en tillståndslös inferenstjänst och lagrar inte användarpromptar, svar eller någon frågehärledd data. Detta är en avtalsmässig garanti enligt GDPR artikel 28 biträdesavtal, inte bara ett policyuttalande. Promptar behandlas i GPU-minnet och kasseras efter att svaret genererats. Operativa loggar innehåller metadata om förfrågan (tidsstämpel, förfrågan-ID, modellversion, latens, tokenantal) men inte promptinnehåll eller svar.
Vilka modeller är tillgängliga via EU-hostad inferens?
JuiceFactory AI ger tillgång till frontmodeller inklusive GPT-4-klass, Claude och Llama-3-70B genom EU-infrastruktur. Modelltillgängligheten ändras regelbundet i takt med att nya versioner blir tillgängliga. Se API-dokumentation för aktuell modellkatalog.
Hur är priserna jämfört med OpenAI?
Privat EU-inferens kostar vanligtvis 1,5-2 gånger så mycket som publika API-priser på grund av dedikerad infrastruktur och efterlevnadskostnader. För organisationer som spenderar mindre än 1 000 EUR/månad på AI kan publika API:er vara mer kostnadseffektiva. För företagsdriftsättningar (10 000+ EUR/månad) motiverar efterlevnadsfördelarna pristillägget. Se portal för detaljerade priser.
Stöder LangChain EU-hostad inferens?
Ja. LangChain och andra OpenAI-kompatibla ramverk fungerar sömlöst med EU-hostade endpoints. Se avsnittet Ramverksintegration ovan för exempel. Alla ramverk som stöder OpenAI:s API kan använda EU-hostad inferens utan modifiering.
Hur kan jag övervaka och observera inferensförfrågningar?
JuiceFactory AI tillhandahåller standardiserade API-svarsheaders inklusive behandlingstid, region och tokenanvändning. För övervakning på applikationsnivå behöver du implementera loggning i ditt applikationslager. Operativa mätetal (latens, felfrekvenser, tokenkonsumtion) kan spåras via din API-dashboard. Eftersom frågor inte sparas på infrastrukturnivå måste frågebaserad analys implementeras i din applikation om det behövs.
Är tillståndslös inferens verkligen GDPR-efterlevande?
Tillståndslös inferens — där frågor behandlas i minnet utan beständig lagring — uppfyller GDPR:s krav på dataminimering (artikel 5.1 c) när den implementeras korrekt. Efterlevnaden bygger på tre tekniska garantier: ingen frågeloggning, korrekt minneslivscykelhantering och ingen lagring av härledda data. JuiceFactory AI implementerar tillståndslös behandling med dessa garantier, vilket gör det möjligt för organisationer att använda inferens enligt GDPR artikel 6.1 f (berättigat intresse) för transient behandling. Organisationer kan verifiera tillståndslös behandling genom infrastrukturrevisioner, nätverksanalys och revisionsrättigheter enligt artikel 28.
Relaterade guider
- RAG with Python: GDPR Document Search - Praktisk implementation av vektorsökning med EU-inferens
- RAG with Qwen: EU-Hosted Embeddings - Använd Qwen-modeller för GDPR-efterlevande RAG
- Stateless LLM API for GDPR - Fördjupning i tillståndslös behandlingsarkitektur
- EU LLM API Comparison - Jämför EU-hostade AI-leverantörer
- Migrate from OpenAI to EU API - Steg-för-steg-migreringsguide