Jak budować aplikacje AI zgodne z RODO przy użyciu prywatnej inferencji w UE
Wprowadzenie: Adopcja AI spotyka się z rzeczywistością zgodności
Sztuczna inteligencja przeszła od eksperymentów do systemów produkcyjnych. Asystenci wyszukiwania, przepływy pracy automatyzacji i narzędzia wspomagania decyzji są teraz częścią codziennych operacji.
Dla zespołów działających w Europie lub obsługujących europejskich użytkowników, jedno ograniczenie staje się nieuniknione: gdzie odbywa się inferencja AI ma takie samo znaczenie jak to, co model może zrobić.
Nawet gdy podstawowe dane są publiczne, zapytania użytkowników, intencje i wzorce interakcji wymagają ostrożnego traktowania. Ten przewodnik wyjaśnia, jak prywatna inferencja AI oparta na UE może być wykorzystana do budowania zgodnych, praktycznych aplikacji AI przy użyciu generowania wspomaganego wyszukiwaniem (RAG).
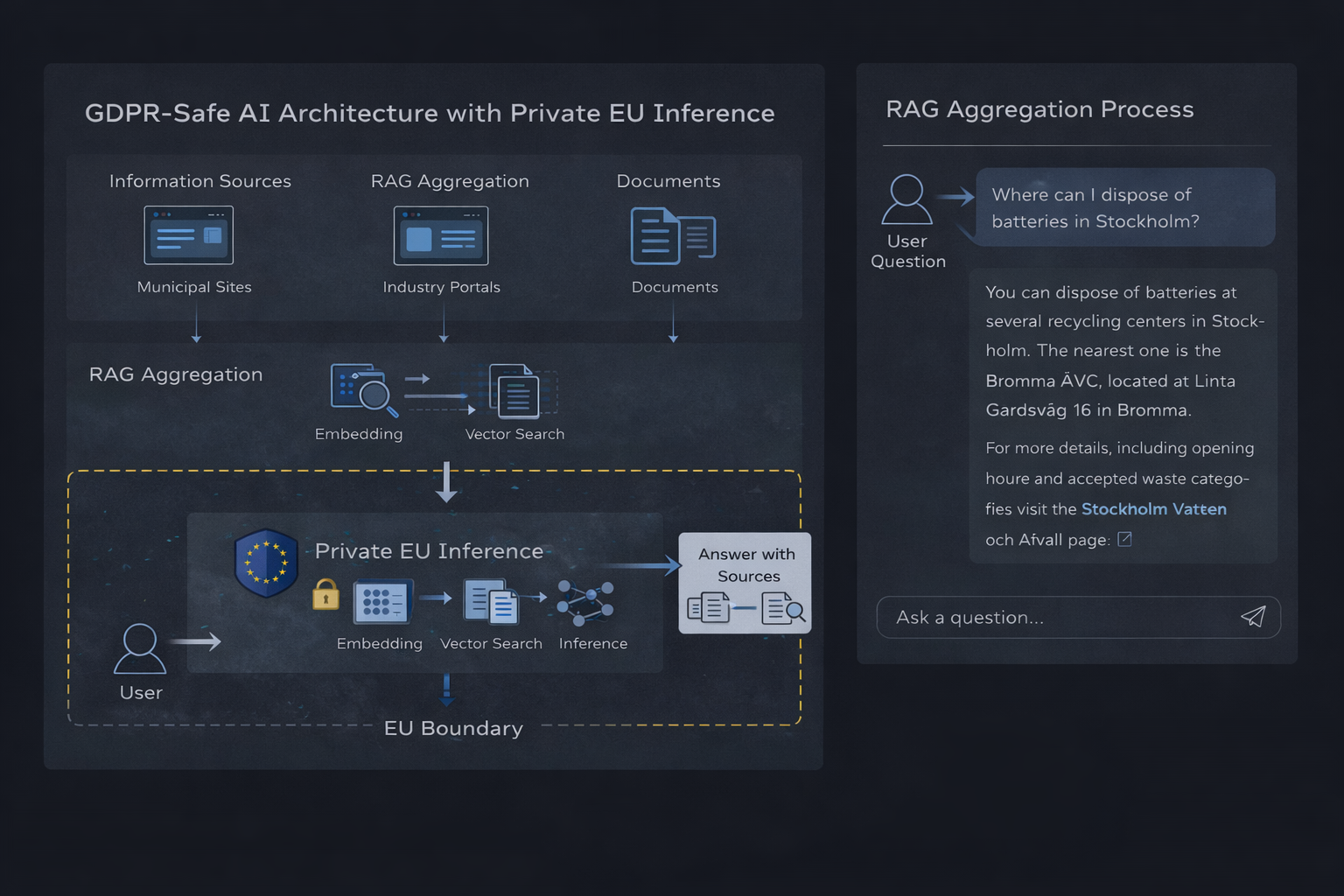 Prywatna architektura inferencji AI oparta na UE z agregacją RAG
Prywatna architektura inferencji AI oparta na UE z agregacją RAG
Kiedy prywatna inferencja AI jest właściwym wyborem
Prywatna inferencja AI nie jest wymagana w każdym przypadku użycia. Staje się istotna, gdy aplikacje muszą działać w ramach jasnych granic danych, przewidywalnego zarządzania i wyraźnych ograniczeń zgodności.
Typowe scenariusze obejmują usługi informacji publicznej, wewnętrzne systemy wiedzy, rurociągi automatyzacji i środowiska regulowane, gdzie lokalizacja danych i kontrola przetwarzania nie podlegają negocjacjom.
Juicefactory.ai zapewnia prywatne środowisko uruchomieniowe inferencji zlokalizowane w UE, zaprojektowane specjalnie dla tych scenariuszy. System nie przechowuje danych osobowych i nie wykorzystuje danych klientów do trenowania modeli. Jego rola ogranicza się wyłącznie do inferencji.
Architektura techniczna: generowanie wspomagane wyszukiwaniem
Generowanie wspomagane wyszukiwaniem łączy tradycyjne wyszukiwanie z rozumowaniem modelu językowego. Zamiast pytać model o swobodną odpowiedź, system pobiera zweryfikowany kontekst i ogranicza odpowiedź do tych informacji.
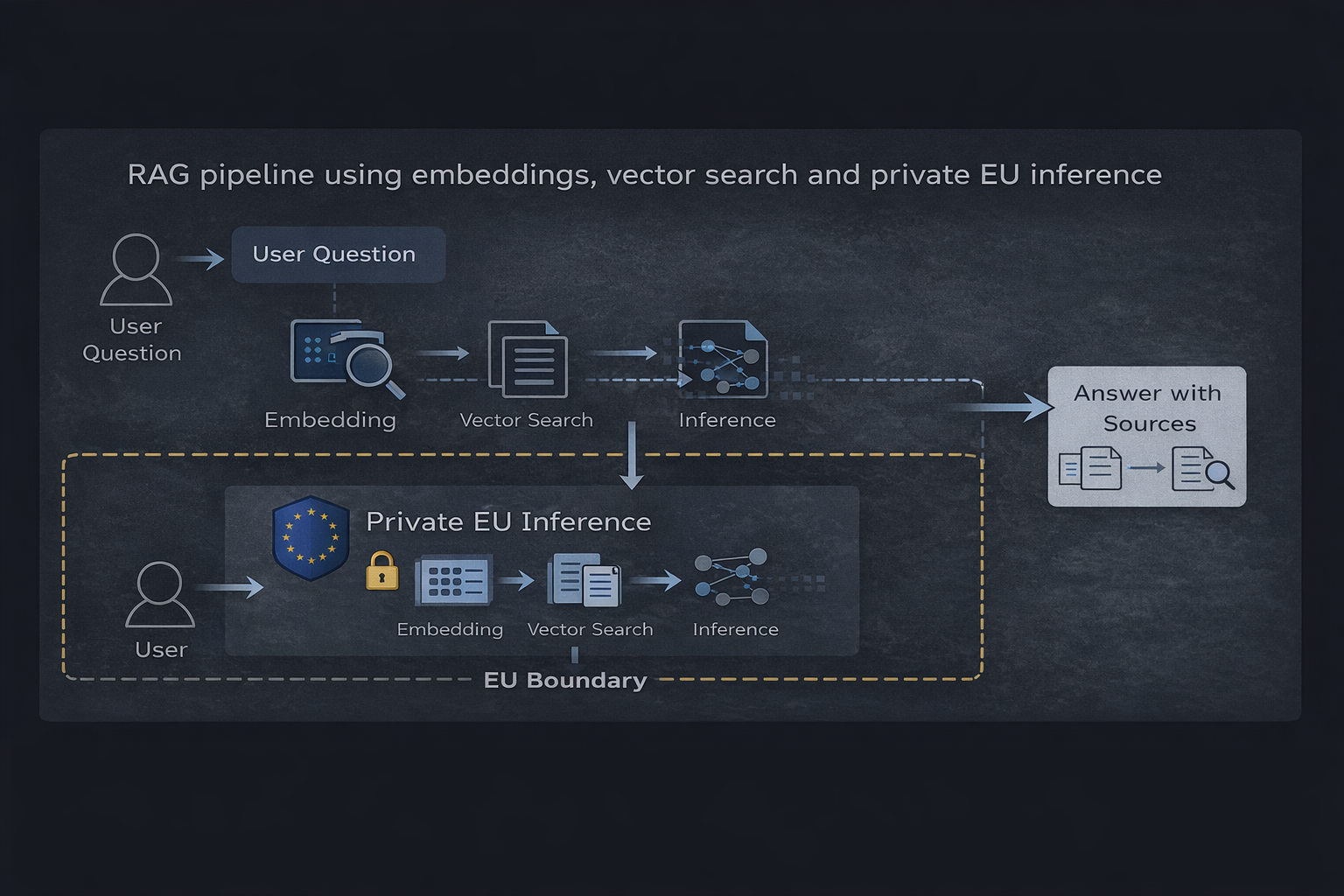 Rurociąg RAG wykorzystujący embeddingi, wyszukiwanie wektorowe i prywatną inferencję w UE
Rurociąg RAG wykorzystujący embeddingi, wyszukiwanie wektorowe i prywatną inferencję w UE
Główne komponenty
- Baza danych wektorowych (taka jak Qdrant) przechowująca zindeksowaną treść
- Embeddingi używane do reprezentowania dokumentów i pytań
- Warstwa pobierania wybierająca istotny kontekst
- Prywatne środowisko uruchomieniowe inferencji generujące uzasadnione odpowiedzi
Przepływ jest prosty: pytanie użytkownika jest osadzane, pobierane są istotne informacje, a model tworzy odpowiedź opartą wyłącznie na tym kontekście.
Praktyczny przykład: uproszczenie dostępu do informacji publicznej
Informacje publiczne są często rozproszone w wielu autorytatywnych źródłach. Strony internetowe gmin, portale branżowe i oficjalne dokumenty mogą zawierać poprawne informacje, ale nadal być trudne do nawigacji dla użytkowników.
Praktyczny przykład tego podejścia można zobaczyć w rzeczywistym eksperymencie, który bada, jak AI może uprościć dostęp do informacji rozdrobnionych narodowo bez zastępowania lokalnego autorytetu.
System pobiera istotną treść, generuje wyjaśnienie i kieruje użytkowników do prawidłowego autorytatywnego źródła — redukując tarcie przy zachowaniu zaufania.
 Przykład działającego asystenta informacji publicznej wykorzystującego generowanie wspomagane wyszukiwaniem i prywatną inferencję opartą na UE.
Przykład działającego asystenta informacji publicznej wykorzystującego generowanie wspomagane wyszukiwaniem i prywatną inferencję opartą na UE.
Dlaczego lokalizacja inferencji ma znaczenie dla RODO
Nawet gdy podstawowa treść jest publiczna, proces inferencji interpretuje intencję użytkownika i zapytania kontekstowe. To przetwarzanie może podlegać rozważaniom RODO, co czyni lokalizację inferencji i praktyki obsługi danych krytycznymi.
Uruchamianie inferencji w UE zapewnia wyraźniejsze granice regulacyjne, przewidywalne zarządzanie i większą przejrzystość zarówno dla operatorów, jak i użytkowników.
Podsumowanie
Prywatna inferencja AI oparta na UE umożliwia połączenie nowoczesnych możliwości AI z odpowiedzialnym zarządzaniem danymi. Łącząc generowanie wspomagane wyszukiwaniem z kontrolowanym środowiskiem uruchomieniowym inferencji, zespoły mogą budować przydatne, zgodne systemy bez poświęcania użyteczności lub kontroli.
Odkryj, jak zastępowanie zewnętrznych dostawców inferencji infrastrukturą opartą na UE działa w praktyce, lub dowiedz się, jak przepływy pracy automatyzacji integrują się z prywatną AI dla zgodności end-to-end.