Hoe GDPR-veilige AI-applicaties bouwen met private EU-inferentie
Introductie: AI-adoptie ontmoet compliance-realiteit
Kunstmatige intelligentie is verschoven van experimenten naar productiesystemen. Zoekassistenten, automatiseringsworkflows en beslissingsondersteunende tools maken nu deel uit van de dagelijkse activiteiten.
Voor teams die in Europa opereren, of Europese gebruikers bedienen, wordt één beperking onvermijdelijk: waar AI-inferentie plaatsvindt is net zo belangrijk als wat het model kan doen.
Zelfs wanneer onderliggende gegevens openbaar zijn, vereisen gebruikersquery's, intenties en interactiepatronen zorgvuldige behandeling. Deze gids legt uit hoe private op de EU gebaseerde AI-inferentie kan worden gebruikt om compliant, praktische AI-applicaties te bouwen met behulp van retrieval-augmented generation (RAG).
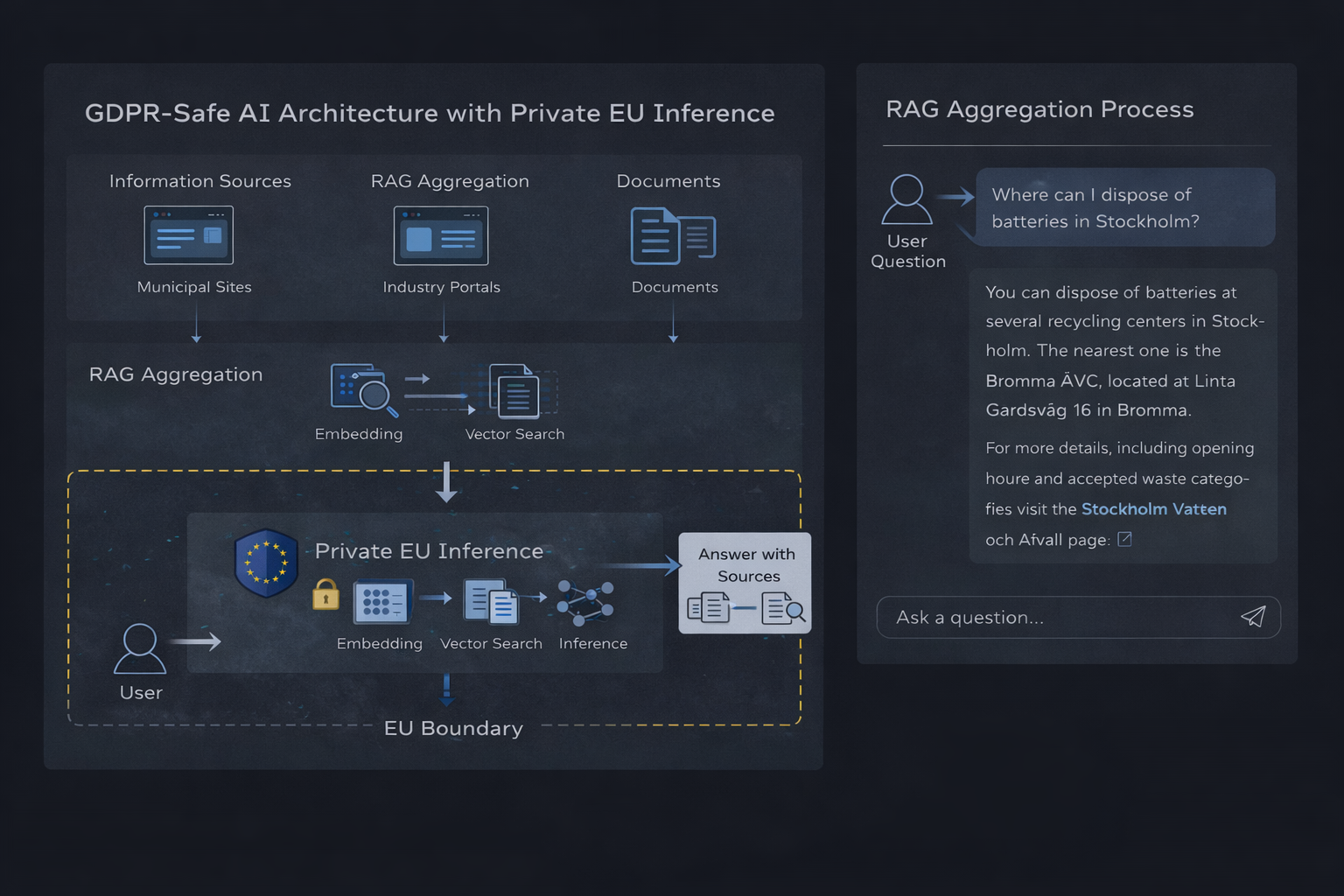 Private op de EU gebaseerde AI-inferentie-architectuur met RAG-aggregatie
Private op de EU gebaseerde AI-inferentie-architectuur met RAG-aggregatie
Wanneer private AI-inferentie de juiste keuze is
Private AI-inferentie is niet vereist voor elk gebruiksgeval. Het wordt relevant wanneer applicaties moeten opereren binnen duidelijke gegevensgrenzen, voorspelbaar bestuur en expliciete compliance-beperkingen.
Typische scenario's omvatten openbare informatiediensten, interne kennissystemen, automatiseringspipelines en gereguleerde omgevingen waar gegevenslokalisatie en verwerkingscontrole niet onderhandelbaar zijn.
Juicefactory.ai biedt een private inferentie-runtime gevestigd in de EU, speciaal ontworpen voor deze scenario's. Het systeem slaat geen persoonsgegevens op en gebruikt geen klantgegevens voor modeltraining. Zijn rol is beperkt tot alleen inferentie.
Technische architectuur: retrieval-augmented generation
Retrieval-augmented generation combineert traditioneel zoeken met taalmodelredenering. In plaats van een model vrij te laten antwoorden, haalt het systeem geverifieerde context op en beperkt het antwoord tot die informatie.
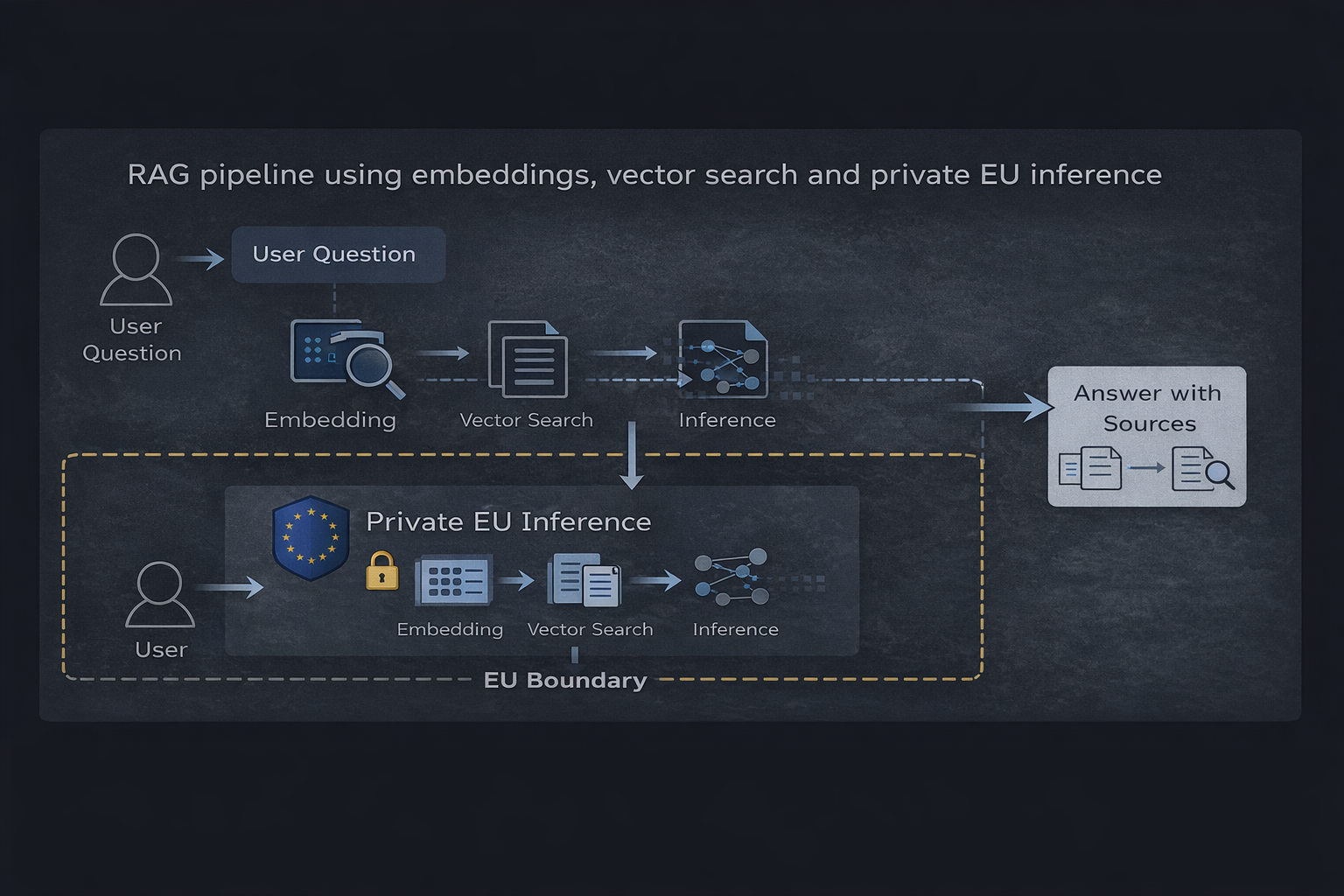 RAG-pipeline met embeddings, vectorzoeken en private EU-inferentie
RAG-pipeline met embeddings, vectorzoeken en private EU-inferentie
Kerncomponenten
- Een vectordatabase (zoals Qdrant) die geïndexeerde inhoud opslaat
- Embeddings gebruikt om documenten en vragen te representeren
- Een ophaalaag die relevante context selecteert
- Een private inferentie-runtime die gefundeerde antwoorden genereert
De flow is eenvoudig: een gebruikersvraag wordt ingebed, relevante informatie wordt opgehaald en het model produceert een antwoord uitsluitend op basis van die context.
Praktisch voorbeeld: toegang tot openbare informatie vereenvoudigen
Openbare informatie is vaak verspreid over veel gezaghebbende bronnen. Gemeentelijke websites, brancheportalen en officiële documenten kunnen allemaal correcte informatie bevatten, maar toch moeilijk te navigeren zijn voor gebruikers.
Een praktisch voorbeeld van deze benadering is te zien in een experiment uit de echte wereld dat onderzoekt hoe AI de toegang tot nationaal gefragmenteerde informatie kan vereenvoudigen zonder lokaal gezag te vervangen.
Het systeem haalt relevante inhoud op, genereert een uitleg en wijst gebruikers naar de juiste gezaghebbende bron — vermindert wrijving terwijl vertrouwen behouden blijft.
 Voorbeeld van een live openbare-informatie-assistent die retrieval-augmented generation en private op de EU gebaseerde inferentie gebruikt.
Voorbeeld van een live openbare-informatie-assistent die retrieval-augmented generation en private op de EU gebaseerde inferentie gebruikt.
Waarom inferentielocatie belangrijk is voor AVG
Zelfs wanneer onderliggende inhoud openbaar is, interpreteert het inferentieproces gebruikersintentie en contextuele query's. Deze verwerking kan onder AVG-overwegingen vallen, wat inferentielocatie en gegevensverwerkingspraktijken kritisch maakt.
Inferentie binnen de EU uitvoeren biedt duidelijkere regelgevende grenzen, voorspelbaar bestuur en grotere transparantie voor zowel operators als gebruikers.
Samenvatting
Private op de EU gebaseerde AI-inferentie maakt het mogelijk om moderne AI-mogelijkheden te combineren met verantwoorde gegevensverwerking. Door retrieval-augmented generation te koppelen aan een gecontroleerde inferentie-runtime, kunnen teams nuttige, compliant systemen bouwen zonder bruikbaarheid of controle op te offeren.
Ontdek hoe het vervangen van externe inferentie-providers met op de EU gebaseerde infrastructuur in de praktijk werkt, of leer hoe automatiseringsworkflows integreren met private AI voor end-to-end compliance.