Applications IA conformes au RGPD : inférence privée dans l'UE avec RAG (guide d'architecture)
Construire des applications IA qui traitent les requêtes des utilisateurs exige une attention particulière aux exigences de conformité au RGPD. Même lorsque les données sous-jacentes sont publiques, l'intention de l'utilisateur, ses schémas de recherche et ses données d'interaction constituent des données personnelles soumises à la réglementation sur la protection des données.
Ce guide propose une architecture technique pour concevoir des applications IA conformes au RGPD en combinant l'inférence privée hébergée dans l'UE avec la génération augmentée par récupération (RAG). Cette approche s'adresse aux équipes d'ingénierie et aux professionnels de la conformité qui doivent intégrer des capacités IA tout en respectant les exigences réglementaires.
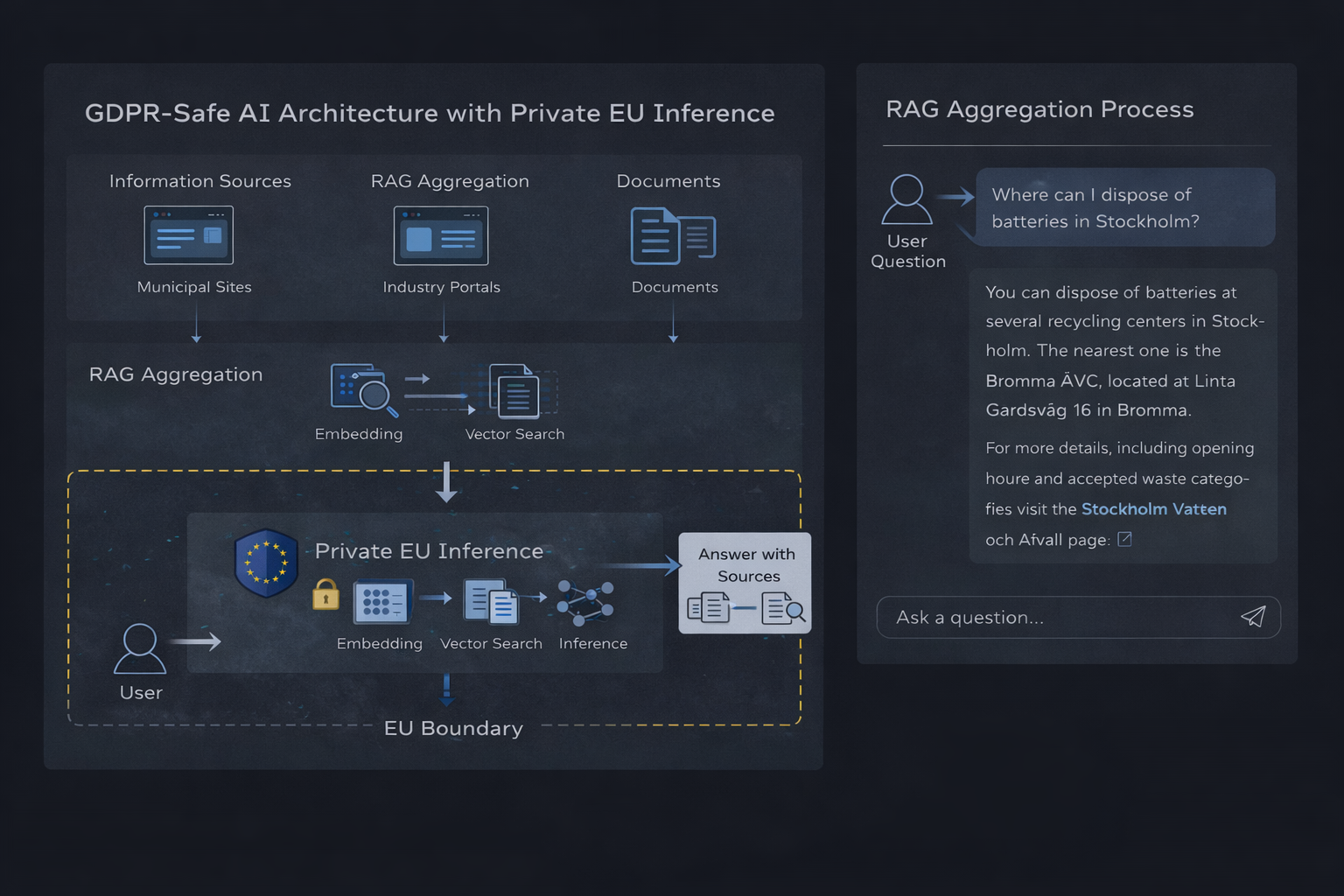 Architecture d'inférence IA privée basée dans l'UE avec agrégation RAG
Architecture d'inférence IA privée basée dans l'UE avec agrégation RAG
Démarrage rapide
Si vous utilisez déjà OpenAI et souhaitez simplement basculer vers un hébergement conforme au RGPD dans l'UE, voici comment procéder :
from openai import OpenAI
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explain GDPR Article 28 requirements."}]
)
print(response.choices[0].message.content)
C'est tout. Aucune modification de code au-delà de l'URL de base et de la clé API. Vos requêtes sont désormais traitées sur une infrastructure européenne avec des garanties contractuelles sur le traitement des données. Consultez le guide de migration pour plus de détails.
Exigences de conformité au RGPD pour l'inférence IA
La conformité au RGPD des systèmes d'IA repose sur trois principes fondamentaux : la minimisation des données, la limitation des finalités et la compétence territoriale.
La minimisation des données impose de ne traiter que les données strictement nécessaires à la finalité définie. Dans le cadre de l'inférence IA, cela signifie éviter le stockage des requêtes utilisateur, de l'historique des conversations ou des informations dérivées au-delà de ce qui est opérationnellement requis.
La limitation des finalités restreint l'utilisation des données traitées à la finalité déclarée. Les fournisseurs d'IA qui exploitent les requêtes de leurs clients pour améliorer leurs modèles ou entraîner de futures versions enfreignent ce principe. Les systèmes conformes doivent mettre en place une isolation stricte entre les opérations d'inférence et toute forme de conservation des données ou d'entraînement de modèle.
La compétence territoriale détermine quel cadre réglementaire s'applique. L'article 3 du RGPD établit que le traitement des données des résidents de l'UE relève de la juridiction européenne, indépendamment du lieu d'établissement de l'organisation. Cela fait de la localisation physique de l'infrastructure d'inférence une exigence de conformité, et non une simple préférence architecturale.
L'inférence privée hébergée dans l'UE répond à ces exigences en :
- Traitant les requêtes en temps réel sans stockage persistant
- Isolant les données client des pipelines d'entraînement des modèles
- Exploitant l'infrastructure d'inférence sur le territoire de l'UE
- Fournissant des garanties contractuelles sur le traitement des données et les relations sous-traitant/responsable de traitement (article 28)
Juicefactory.ai agit en qualité de sous-traitant au sens de l'article 28 du RGPD, avec des accords de traitement documentés et des garanties techniques sur la gestion des données. Aucune requête n'est conservée, aucune donnée n'est utilisée pour l'entraînement, et tout le traitement s'effectue sur une infrastructure européenne. Voir le runtime d'inférence privée pour plus de détails.
Pourquoi l'hébergement dans l'UE est déterminant pour la conformité
La localisation physique de l'infrastructure d'inférence IA a un impact direct sur la conformité réglementaire, la souveraineté des données et l'opposabilité juridique.
Clarté réglementaire : une infrastructure hébergée dans l'UE fonctionne sous un cadre réglementaire unifié. Lorsque l'inférence s'exécute dans l'UE, les autorités de protection des données disposent d'une compétence claire, les sous-traitants opèrent sous des exigences juridiques connues, et les personnes concernées bénéficient de droits opposables selon des procédures établies.
Suppression des transferts de données : le chapitre V du RGPD impose des conditions strictes pour les transferts de données vers des pays tiers. Les transferts UE-États-Unis nécessitent des décisions d'adéquation, des clauses contractuelles types ou des mécanismes alternatifs qui engendrent une charge de conformité et une incertitude juridique. Conserver l'inférence sur le territoire européen élimine purement et simplement ces exigences de transfert.
Responsabilité du sous-traitant : en vertu de l'article 28 du RGPD, les sous-traitants doivent démontrer leur conformité par des mesures techniques et organisationnelles. Les sous-traitants établis dans l'UE sont directement supervisés par les autorités de protection des données, soumis aux mêmes obligations de notification des violations et contrôlables selon des procédures établies.
Souveraineté et contrôle : l'hébergement dans l'UE garantit que les procédures judiciaires, les demandes gouvernementales et les accès aux données suivent le droit européen. Un hébergement hors UE peut soumettre les données à des cadres juridiques étrangers, à une surveillance extraterritoriale ou à des obligations juridiques contradictoires.
La conséquence pratique pour les systèmes IA est limpide : l'hébergement dans l'UE transforme la conformité d'un effort juridique permanent en une garantie architecturale.
Architecture RAG pour la conformité au RGPD
La génération augmentée par récupération (RAG) combine la recherche d'informations avec l'inférence d'un modèle de langage pour produire des réponses fondées et vérifiables. L'architecture se compose de quatre composants distincts, chacun avec des considérations de conformité spécifiques.
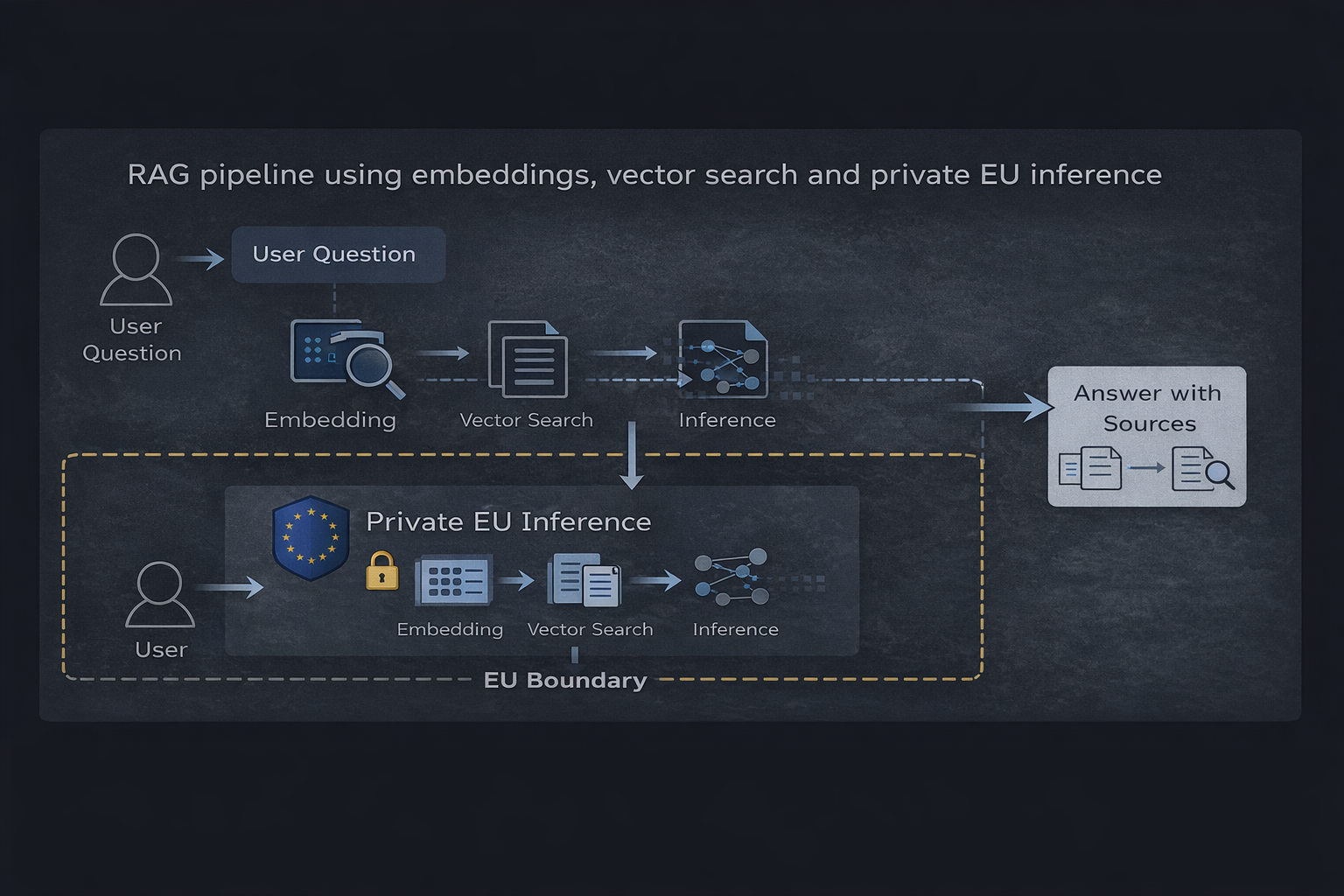 Pipeline RAG utilisant des embeddings, recherche vectorielle et inférence privée dans l'UE
Pipeline RAG utilisant des embeddings, recherche vectorielle et inférence privée dans l'UE
Vue d'ensemble de l'architecture
1. Base de données vectorielle : elle stocke les représentations vectorielles des documents sources. La base contient des données dérivées (embeddings) plutôt que des requêtes utilisateur brutes, ce qui la rend compatible avec un stockage persistant sous réserve de contrôles d'accès appropriés.
2. Service d'embedding : il convertit les requêtes utilisateur et les documents en représentations vectorielles. Cette étape de traitement ne doit pas conserver les données de requête ni les utiliser à des fins d'entraînement.
3. Couche de récupération : elle effectue une recherche de similarité vectorielle pour identifier le contexte pertinent. Ce composant traite les requêtes utilisateur de manière transitoire, sans stockage persistant.
4. Runtime d'inférence : il génère les réponses à partir du contexte récupéré. C'est la frontière de conformité critique — le runtime doit traiter les requêtes sans stockage, sans journalisation et sans collecte de données d'entraînement.
Flux de données et frontières de conformité
- L'utilisateur soumet une requête (donnée personnelle au sens du RGPD)
- La requête est vectorisée sans conservation (traitement transitoire)
- La recherche vectorielle récupère le contexte pertinent (aucune donnée personnelle impliquée)
- Le contexte et la requête sont envoyés au runtime d'inférence dans l'UE
- La réponse est générée et renvoyée (aucun stockage de la requête ni de la réponse)
- Optionnel : la réponse est journalisée par la couche applicative (sous le contrôle du client)
La propriété de conformité essentielle de cette architecture est l'isolation : les données personnelles (requêtes utilisateur) traversent le système sans persistance au niveau de l'infrastructure. Toute conservation de données intervient dans la couche applicative, sous le contrôle du client, et non au niveau du fournisseur de services.
Pour un exemple d'implémentation concret, consultez notre guide RAG avec Python.
Choix de la base de données vectorielle (Qdrant, pgvector, etc.)
Le choix de la base de données vectorielle impacte les performances, la complexité opérationnelle et la posture de conformité. Les principales options sont les bases de données vectorielles spécialisées (Qdrant, Weaviate, Milvus), les extensions PostgreSQL (pgvector) et les services managés (Pinecone, AWS OpenSearch).
Qdrant
Qdrant est une base de données vectorielle open source conçue spécifiquement pour la recherche de similarité. Elle prend en charge l'indexation HNSW, la recherche filtrée et les déploiements distribués.
Avantages en matière de conformité :
- Peut être auto-hébergée sur une infrastructure dans l'UE
- Aucune télémétrie ni communication sortante obligatoire
- Frontières de données claires (ne stocke que ce qui est explicitement indexé)
- Compatible avec les déploiements en environnement isolé (air-gapped)
Caractéristiques opérationnelles :
- Nécessite une infrastructure dédiée
- Clustering intégré pour la mise à l'échelle horizontale
- APIs gRPC et HTTP pour l'intégration
pgvector
pgvector est une extension PostgreSQL qui ajoute la recherche de similarité vectorielle aux bases de données PostgreSQL existantes.
Avantages en matière de conformité :
- S'appuie sur l'infrastructure PostgreSQL existante et ses contrôles de conformité
- Aucune dépendance externe supplémentaire
- Les données restent dans le périmètre établi de la base de données
- Modèle opérationnel familier pour les équipes utilisant déjà PostgreSQL
Caractéristiques opérationnelles :
- Limité à la recherche de plus proches voisins approximative (HNSW, IVFFlat)
- Performances adaptées aux jeux de données de petite à moyenne taille (<10M vecteurs)
- Intégration aisée avec les bases de données applicatives existantes
Critères de sélection pour la conformité RGPD
Pour les architectures conformes au RGPD, les facteurs de décision déterminants sont :
- Contrôle de l'hébergement : la base de données peut-elle être déployée sur une infrastructure dans l'UE ?
- Isolation des données : la base collecte-t-elle de la télémétrie, des données d'utilisation ou des métadonnées au-delà de ce qui est explicitement stocké ?
- Expertise opérationnelle : votre équipe a-t-elle la capacité de gérer l'infrastructure ?
Les services managés (Pinecone, Weaviate Cloud) simplifient l'exploitation mais nécessitent une évaluation attentive de leurs accords de traitement des données et de leurs localisations d'hébergement. Les solutions auto-hébergées (Qdrant, pgvector) offrent un contrôle maximal mais exigent une capacité opérationnelle.
Pour la plupart des cas d'usage axés sur la conformité, Qdrant ou pgvector auto-hébergé sur une infrastructure dans l'UE offre la voie de conformité la plus directe. Consultez notre guide RAG avec Qwen pour des exemples d'implémentation.
Modèles d'embedding et considérations de confidentialité
Les modèles d'embedding convertissent le texte en représentations vectorielles destinées à la recherche de similarité. Le choix du modèle d'embedding et son mode d'exploitation ont un impact direct sur la confidentialité et la conformité.
Options de modèles d'embedding
APIs cloud (OpenAI embeddings, Cohere, Voyage) : elles traitent le texte via des services externes. Ces services reçoivent l'intégralité du texte des requêtes utilisateur et des documents. La plupart des fournisseurs cloud d'embedding se réservent explicitement le droit d'utiliser les données d'entrée pour l'amélioration de leurs modèles, ce qui les rend inadaptés aux applications sensibles en matière de confidentialité.
Modèles auto-hébergés (sentence-transformers, nomic-embed, bge-*) : ils s'exécutent sur votre infrastructure et traitent les données localement. Ces modèles offrent un contrôle total sur le flux de données et suppriment les transferts vers des tiers.
Services d'API privés comme Juicefactory.ai : ils fournissent des APIs d'embedding avec des garanties contractuelles sur le traitement des données. Ces services traitent les embeddings sans conservation ni collecte de données d'entraînement, fonctionnant en tant que sous-traitants conformes au RGPD.
Considérations de confidentialité et de conformité
La question de conformité centrale pour les embeddings est la suivante : le service d'embedding voit-il et conserve-t-il les requêtes utilisateur ?
Pour l'indexation de documents, les préoccupations de confidentialité sont minimales — les documents à vectoriser ne sont généralement pas des données personnelles, et l'indexation s'effectue en batch sous votre contrôle.
Pour les embeddings de requêtes, la confidentialité est critique. Chaque requête utilisateur est traitée par le service d'embedding. Si ce service conserve les requêtes, les journalise ou les utilise pour l'entraînement, cela crée une obligation de conformité et un vecteur de fuite potentiel.
Architecture d'embedding conforme :
- Utiliser des modèles d'embedding auto-hébergés pour un contrôle maximal
- En cas d'utilisation d'une API externe d'embedding, vérifier les garanties contractuelles sur le traitement des données
- S'assurer que les services d'embedding agissent en tant que sous-traitants au sens de l'article 28 du RGPD
- Privilégier les services hébergés dans l'UE pour éviter les transferts transfrontaliers de données
Juicefactory.ai fournit des APIs d'embedding en complément de ses services d'inférence, avec les mêmes garanties de conformité : aucune conservation de données, aucune collecte de données d'entraînement, hébergement dans l'UE et accords de sous-traitance. Voir la documentation API pour les détails d'implémentation.
Configuration du runtime d'inférence privée
Le runtime d'inférence est le composant qui traite les requêtes utilisateur et génère les réponses. C'est la frontière de conformité la plus critique de l'architecture.
Exigences de conformité pour l'inférence
Un runtime d'inférence conforme au RGPD doit :
- Traiter les requêtes sans conservation : les requêtes sont traitées en mémoire et supprimées après la génération de la réponse
- Isoler les données client de l'entraînement : aucune donnée de requête, réponse ou information dérivée n'est utilisée pour entraîner ou améliorer les modèles
- Opérer sous juridiction européenne : l'infrastructure fonctionne dans des centres de données de l'UE, sous le cadre juridique européen
- Agir en tant que sous-traitant : le service opère au titre de l'article 28 du RGPD avec des accords de traitement documentés
- Fournir des capacités d'audit : les clients peuvent vérifier la conformité par des mesures techniques et contractuelles
Inférence privée vs. APIs publiques
Les APIs IA publiques (OpenAI, Anthropic, Google) sont conçues pour le développement et l'amélioration des modèles. Leurs conditions d'utilisation accordent généralement des droits étendus d'exploitation des données client à des fins d'entraînement et d'amélioration de la qualité. Même lorsque des mécanismes de « désinscription » existent, ils nécessitent une configuration active et peuvent ne pas couvrir toutes les activités de traitement.
Les services d'inférence privée sont architecturés pour la conformité. Le traitement des données est limité contractuellement, l'infrastructure est dédiée ou isolée, et le service opère en tant que sous-traitant plutôt qu'en tant que responsable de traitement.
Implémentation avec Juicefactory.ai
Juicefactory.ai fournit une inférence privée basée dans l'UE via une API compatible OpenAI. Le service prend en charge :
- Hébergement dans l'UE : toute l'inférence s'exécute dans des centres de données européens
- Aucune conservation de données : les requêtes et les réponses ne sont pas stockées
- Aucune collecte de données d'entraînement : les données client ne sont jamais utilisées pour l'amélioration des modèles
- Accords de sous-traitance : accords de traitement conformes à l'article 28 du RGPD
- Compatibilité API OpenAI : remplacement direct des intégrations OpenAI existantes
Exemple d'implémentation (SDK OpenAI moderne v1.x+) :
from openai import OpenAI
# Configure to use private EU inference
client = OpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here"
)
# Standard OpenAI API calls now route through private EU infrastructure
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain GDPR Article 28 requirements."}
]
)
print(response.choices[0].message.content)
Aucune modification de code n'est nécessaire au-delà de la configuration du point d'accès API. Les applications existantes utilisant les SDKs OpenAI peuvent basculer vers l'inférence privée en mettant à jour l'URL de base et la clé API.
Voir le portail pour les options de déploiement et le guide comparatif pour une analyse des fonctionnalités.
Intégration avec les frameworks
Les frameworks IA modernes fonctionnent parfaitement avec les endpoints compatibles OpenAI. Voici comment les intégrer avec les outils les plus courants :
LangChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.invoke("Explain GDPR data minimization principle")
print(response.content)
LlamaIndex
from llama_index.llms.openai import OpenAI
llm = OpenAI(
api_base="https://api.juicefactory.ai/v1",
api_key="jf_your_key_here",
model="gpt-4"
)
response = llm.complete("Explain GDPR data minimization principle")
print(response.text)
curl (API directe)
curl https://api.juicefactory.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jf_your_key_here" \
-d '{
"model": "gpt-4",
"messages": [{"role": "user", "content": "Explain GDPR Article 28"}]
}'
Tous les frameworks compatibles avec l'API OpenAI fonctionnent sans modification — il suffit de les diriger vers le point d'accès hébergé dans l'UE. Pour d'autres exemples d'intégration, consultez notre guide API LLM sans état.
Pourquoi l'inférence sur GPU unique à haute mémoire est importante pour la conformité
L'architecture de l'infrastructure a un impact direct sur les garanties de conformité au RGPD. L'inférence sur GPU unique à haute mémoire offre des propriétés d'isolation que les systèmes distribués ne peuvent égaler.
Le défi de conformité du sharding de modèle
Les grands modèles de langage dépassent souvent la capacité mémoire d'un seul GPU, imposant un déploiement sur plusieurs GPU ou noeuds. Cette distribution crée des vulnérabilités en matière de protection des données :
Risque de fuite inter-noeuds : lorsqu'un modèle est fragmenté sur plusieurs GPU ou serveurs, les données de requête transitent par plusieurs espaces mémoire. Chaque frontière représente un point de fuite potentiel. Les outils de débogage, les dumps mémoire ou les défaillances système peuvent exposer des fragments de requête à travers l'infrastructure.
Surface d'attaque élargie : chaque noeud supplémentaire multiplie la surface d'attaque. Les attaques par canal auxiliaire mémoire (variantes Spectre, Meltdown) deviennent plus efficaces lorsque les données de requête sont distribuées sur une infrastructure partagée.
Avantages du GPU unique pour la conformité RGPD
Les GPU à haute mémoire (96 Go, 128 Go ou plus) peuvent héberger de grands modèles (70B paramètres, classe GPT-4) dans un seul espace mémoire. Cette simplification architecturale procure des avantages en termes de conformité :
Isolation prévisible : toute l'inférence s'effectue dans la mémoire d'un seul GPU. Les données de requête ne traversent jamais de frontières mémoire, d'interfaces réseau ou de canaux de communication inter-processus. Le chemin des données est déterministe et auditable.
Traitement atomique : chaque requête entre dans la mémoire GPU, subit l'inférence, produit une réponse et est supprimée — entièrement dans les limites du silicium. Aucun stockage intermédiaire, aucune coordination inter-noeuds, aucune donnée résiduelle en mémoire système.
Rayon d'impact réduit : les incidents de sécurité sont confinés à un seul GPU. Les compromissions mémoire ne peuvent pas se propager à travers l'infrastructure, ce qui limite le périmètre d'exposition.
Modèle d'infrastructure JuiceFactory
JuiceFactory AI exécute l'inférence sur des GPU dédiés à haute mémoire (96 Go+) faisant tourner des instances mono-modèle :
- Pas de sharding de modèle : chaque GPU héberge un modèle complet dans sa propre mémoire
- Pas de multi-tenancy au niveau GPU : les requêtes des clients ne partagent pas l'espace mémoire GPU
- Traitement éphémère : la mémoire GPU est nettoyée entre chaque requête
- Traitement mono-région : les requêtes ne transitent jamais par d'autres régions
| Architecture | Efficacité mémoire | Auditabilité de conformité | Garanties d'isolation |
|---|---|---|---|
| Distribuée (4x24 Go) | Elevée | Complexe | Probabiliste |
| GPU unique (96 Go) | Modérée | Simple | Déterministe |
Pour les applications critiques au regard du RGPD, le modèle GPU unique offre la voie de conformité la plus directe.
Exemple concret : assistant d'information publique
Les systèmes d'information publique constituent un cas d'usage caractéristique de l'IA conforme au RGPD : même lorsque les données sous-jacentes sont publiques, les requêtes des utilisateurs révèlent leur intention, leurs centres d'intérêt et leurs besoins en information, autant d'éléments qui constituent des données personnelles.
Architecture : assistant d'information sur les entreprises suédoises
Une implémentation concrète de cette architecture est visible dans un assistant d'information publique sur les entreprises suédoises. Le système agrège des informations sur les entreprises provenant de multiples sources faisant autorité (Bolagsverket, administration fiscale, registres sectoriels) et offre une interface en langage naturel pour les interrogations.
Caractéristiques des données :
- Toutes les données sources sont publiques (enregistrements d'entreprises, rapports financiers, registres publics)
- Les requêtes des utilisateurs révèlent des intérêts commerciaux, de la veille concurrentielle et des intentions d'investigation
- Le système dessert à la fois des utilisateurs suédois et européens
Implémentation technique :
- Indexation des documents : données d'entreprises publiques indexées dans une instance Qdrant auto-hébergée
- Embeddings : documents et requêtes vectorisés via un service d'embedding hébergé dans l'UE
- Récupération : la recherche de similarité vectorielle identifie les informations pertinentes sur l'entreprise
- Inférence : l'inférence privée Juicefactory.ai dans l'UE génère des réponses en langage naturel
- Réponse : la réponse est renvoyée avec des citations vers les sources faisant autorité
Posture de conformité :
- Requêtes utilisateur traitées sans conservation (traitement transitoire au titre de l'article 6(1)(f) du RGPD)
- Toute l'infrastructure de traitement localisée dans l'UE
- Aucun transfert de données vers des pays tiers
- Le service opère en qualité de sous-traitant avec des accords documentés
Cette architecture démontre que la conformité au RGPD n'implique pas de sacrifier la fonctionnalité. Le système offre des capacités IA modernes tout en maintenant des frontières strictes de traitement des données.
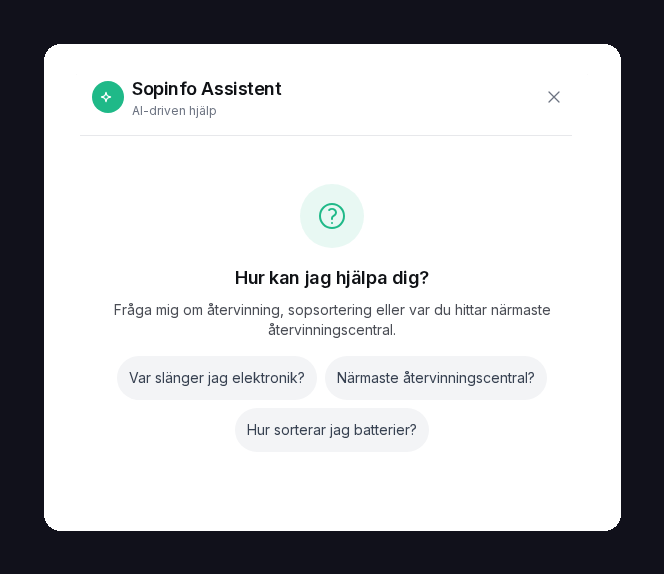 Exemple d'un assistant d'information publique en direct utilisant la génération augmentée par récupération et l'inférence privée basée dans l'UE.
Exemple d'un assistant d'information publique en direct utilisant la génération augmentée par récupération et l'inférence privée basée dans l'UE.
Synthèse et prochaines étapes
Les applications IA conformes au RGPD exigent des décisions architecturales à chaque couche : les bases de données vectorielles doivent être déployées avec un contrôle sur la localisation des données, les modèles d'embedding doivent traiter les requêtes sans conservation, et les runtimes d'inférence doivent opérer en tant que sous-traitants conformes sous juridiction européenne.
L'architecture RAG présentée dans ce guide propose un chemin d'implémentation concret :
- Base de données vectorielle : Qdrant ou pgvector auto-hébergé sur une infrastructure dans l'UE
- Embeddings : modèles auto-hébergés ou services d'API dans l'UE avec accords de sous-traitance
- Inférence : runtime privé dans l'UE avec garanties contractuelles sur le traitement des données
- Couche applicative : politiques de journalisation et de conservation des données sous contrôle du client
Cette architecture transforme la conformité d'un effort juridique continu en une garantie structurelle. En choisissant une infrastructure qui ne peut pas violer les exigences du RGPD, les équipes d'ingénierie peuvent construire des applications IA sans charge de conformité permanente.
Ressources d'implémentation
- Pour commencer : créer une clé API pour l'inférence privée dans l'UE
- Migration : migrer depuis OpenAI avec des instructions pas à pas
- Comparatif : comparaison des APIs LLM européennes pour évaluer les fournisseurs
- Tarification : options de déploiement pour la mise en production
Foire aux questions
Le RGPD s'applique-t-il si je ne traite que des données publiques ?
Le RGPD s'applique en fonction du traitement de données personnelles, et non de la nature des données sources. Même lorsque les informations sous-jacentes sont publiques, les requêtes utilisateur, les schémas de recherche et les journaux d'interaction constituent des données personnelles au sens de l'article 4(1) du RGPD. Si votre système traite des requêtes de résidents de l'UE, le RGPD s'applique indépendamment du caractère public des réponses fournies.
L'hébergement dans l'UE est-il juridiquement obligatoire pour la conformité au RGPD ?
L'hébergement dans l'UE n'est pas strictement obligatoire — le RGPD autorise les transferts de données vers des pays tiers selon les mécanismes du chapitre V (décisions d'adéquation, clauses contractuelles types, règles d'entreprise contraignantes). Cependant, ces mécanismes engendrent une charge de conformité, une incertitude juridique et une complexité opérationnelle. L'hébergement dans l'UE supprime entièrement les exigences de transfert, offrant une voie de conformité plus simple et plus robuste.
Comment les systèmes RAG réduisent-ils le risque de conformité par rapport aux modèles affinés ?
Les systèmes RAG séparent le stockage des données (base de données vectorielle) de l'inférence du modèle (runtime LLM). Les données utilisateur influencent la génération de la réponse via le contexte récupéré, mais ne modifient pas les poids du modèle. Cette séparation architecturale permet de contrôler la conservation des données, d'auditer les flux de données et de mettre en oeuvre un traitement conforme. Les modèles affinés (fine-tuned), à l'inverse, incorporent les données d'entraînement dans les poids du modèle, ce qui rend difficile la suppression de points de données spécifiques ou l'audit de l'influence des données.
Quelle est la différence entre un sous-traitant et un responsable de traitement pour les services IA ?
Au sens de l'article 4 du RGPD, un responsable de traitement détermine les finalités et les moyens du traitement, tandis qu'un sous-traitant traite les données pour le compte du responsable de traitement. Pour les services IA, vous (le développeur d'application) êtes généralement le responsable de traitement, et le fournisseur de services IA est le sous-traitant. Cette distinction est importante car les sous-traitants opèrent selon vos instructions et doivent signer des accords de traitement des données (article 28) limitant leur utilisation des données. Les services d'inférence privée agissent en tant que sous-traitants ; les APIs IA publiques fonctionnent souvent en tant que responsables de traitement ou revendiquent un statut de responsable conjoint.
Puis-je utiliser cette architecture pour des applications internes destinées aux employés ?
Oui. Le RGPD s'applique aux données des employés avec la même rigueur qu'aux données des clients. Les applications IA internes qui traitent les requêtes des employés, les informations RH ou les documents métier nécessitent les mêmes mesures de conformité. L'architecture décrite dans ce guide s'applique de la même manière aux applications internes et externes.
JuiceFactory conserve-t-il les prompts utilisateur ?
Non. JuiceFactory AI fonctionne comme un service d'inférence sans état et ne conserve pas les prompts utilisateur, les réponses ni aucune donnée dérivée des requêtes. Il s'agit d'une garantie contractuelle au titre des accords de traitement de l'article 28 du RGPD, et non d'une simple déclaration de politique. Les prompts sont traités dans la mémoire GPU et supprimés après la génération de la réponse. Les journaux opérationnels contiennent des métadonnées de requête (horodatage, identifiant de requête, version du modèle, latence, nombre de tokens) mais pas le contenu des prompts ni les réponses.
Quels modèles sont disponibles via l'inférence hébergée dans l'UE ?
JuiceFactory AI donne accès à des modèles de pointe, notamment GPT-4, Claude et Llama-3-70B, via une infrastructure européenne. La disponibilité des modèles évolue régulièrement à mesure que de nouvelles versions sont publiées. Consultez la documentation API pour le catalogue de modèles actuel.
Comment les tarifs se comparent-ils à ceux d'OpenAI ?
L'inférence privée dans l'UE coûte généralement 1,5 à 2 fois le tarif des APIs publiques, en raison de l'infrastructure dédiée et de la surcharge liée à la conformité. Pour les organisations dépensant moins de 1 000 EUR par mois en IA, les APIs publiques peuvent être plus rentables. Pour les déploiements d'entreprise (10 000 EUR+/mois), les avantages en matière de conformité justifient le surcoût. Consultez le portail pour les tarifs détaillés.
LangChain prend-il en charge l'inférence hébergée dans l'UE ?
Oui. LangChain et les autres frameworks compatibles OpenAI fonctionnent parfaitement avec les endpoints hébergés dans l'UE. Consultez la section Intégration avec les frameworks ci-dessus pour des exemples. Tout framework supportant l'API OpenAI peut utiliser l'inférence hébergée dans l'UE sans modification.
Comment surveiller et observer les requêtes d'inférence ?
JuiceFactory AI fournit des en-têtes de réponse API standard incluant le temps de traitement, la région et l'utilisation des tokens. Pour la surveillance au niveau applicatif, vous devrez implémenter la journalisation dans votre couche applicative. Les métriques opérationnelles (latence, taux d'erreur, consommation de tokens) peuvent être suivies via votre tableau de bord API. Puisque les requêtes ne sont pas conservées au niveau de l'infrastructure, les analyses au niveau des requêtes doivent être implémentées dans votre application si nécessaire.
L'inférence sans état est-elle véritablement conforme au RGPD ?
L'inférence sans état — où les requêtes sont traitées en mémoire sans stockage persistant — satisfait les exigences de minimisation des données du RGPD (article 5(1)(c)) lorsqu'elle est correctement implémentée. La conformité repose sur trois garanties techniques : aucune journalisation des requêtes, une gestion appropriée du cycle de vie de la mémoire et aucune conservation de données dérivées. JuiceFactory AI met en oeuvre un traitement sans état avec ces garanties, permettant aux organisations d'invoquer l'inférence au titre de l'article 6(1)(f) du RGPD (intérêt légitime) pour le traitement transitoire. Les organisations peuvent vérifier le traitement sans état par des audits d'infrastructure, une analyse réseau et les droits d'audit de l'article 28.
Guides connexes
- RAG with Python: GDPR Document Search - Implémentation pratique de la recherche vectorielle avec inférence dans l'UE
- RAG with Qwen: EU-Hosted Embeddings - Utilisation des modèles Qwen pour un RAG conforme au RGPD
- Stateless LLM API for GDPR - Approfondissement sur l'architecture de traitement sans état
- EU LLM API Comparison - Comparaison des fournisseurs d'IA hébergés dans l'UE
- Migrate from OpenAI to EU API - Guide de migration pas à pas